Introduction
Last summer I have discovered several vulnerabilities in the implementation of Samsung’s NPU device driver. While I was working on completing my proof of concept exploit, Ben Hawkes from Google’s Project Zero reported the same vulnerabilities to Samsung. Later that year Brandon Azad released an article documenting his approach of turning these bugs into an arbitrary kernel code execution exploit. At the same time, the team of aSiagaming, yeonnic, and say2 also found the same bugs and published a writeup, focusing on their method of exploitation and the post exploitation steps required to obtain root.
What makes the initial bugs interesting, besides the triple collision, is that they provide two very distinct avenues for exploitation. Both Brandon Azad and aSiagaming et al. decided to leverage the vmap out-of-bound write to compromize the kernel. My proof of concept exploit utilizes the race condition and the consequential heap overflow to achieve arbitrary kernel read-write. Kmalloc overflow exploitation is not a novel concept, but the combination of modern Android kernel mitigations and limitations of the original exploit primitive provided by the vulnerability created interesting challenges.
In this blog post I briefly introduce the vulnerabilities in the NPU driver and detail my journey through the exploitation process. I will focus on where previously published techniques fall short and how surprisingly old techniques remain applicable. I will also discuss the kernel instrumentation I have created to assist the kernel heap exploit development in a constrained environment that is a production Samsung Android phone.
I’ve finished this proof of concept exploit during Fall 2020, but this publication was delayed until we finally got the website up and got around to writing the story.
SVE-2020-18610
The Samsung NPU (Neural Processing Unit) is an additional processing core within the Exynos SoC that allows efficient, hardware accelerated execution of pretrained neural network models. It allows features such as Shot Suggestion, Scene Optimizer, AI Gallery, and so on to function in real time, while processing the image data coming from the camera. As far as I know, the NPU was first introduced on the S9 series devices, in a preliminary form, and it was significantly improved and overhauled for the S10 and S20 series phones. Originally, Samsung released an SDK that allowed applications to exercise the capabilities of this core but since last year it is no longer available to third parties. For the interested reader, Maxime Peterlin does a fantastic job documenting the inner workings of the NPU firmware, the inter-chip IPC communication and the kernel driver in his article.
The NPU is exposed to the user space through the /dev/vertex10 character device, which implements a lightweight V4L2 (Video4Linux2) Videbuf2 inspired streaming API. This kernel driver provides ioctl handlers to upload neural network models, set image parameters, allocate buffers and manage streams. The vulnerabilities are in the VS4L_VERTEXIOC_S_GRAPH ioctl implementation, inside the npu_vertex_s_graph() function. This ioctl is used to initialize a new graph representing a neural network model. Vaguely described, it receives an ION buffer fd, maps it into the kernel virtual address space and processes the graph data from it.
The ION allocator is used to request physically contiguous memory, represented by a file descriptor, that can be shared between user space applications, the kernel, and external cores. In the case of the vulnerable ioctl, user space allocates the buffer, mmaps it into its own address space, initializes the content of it and passes the fd to the kernel driver. The kernel driver calls __get_session_info() to receive the input data, and map the ION buffer into kernel and device memory (by invoking __ncp_ion_map()). The main takeaway is that the content of the ION buffer is supplied by user space and the kernel does not have exclusive access to this memory while operating on it.
The subsequent __config_session_info function is responsible for the parsing of the graph data.
int __config_session_info(struct npu_session *session)
{
[...]
struct temp_av *temp_IFM_av;
struct temp_av *temp_OFM_av;
struct temp_av *temp_IMB_av;
struct addr_info *WGT_av;
ret = __pilot_parsing_ncp(session, &temp_IFM_cnt, &temp_OFM_cnt, &temp_IMB_cnt, &WGT_cnt);
temp_IFM_av = kcalloc(temp_IFM_cnt, sizeof(struct temp_av), GFP_KERNEL);
temp_OFM_av = kcalloc(temp_OFM_cnt, sizeof(struct temp_av), GFP_KERNEL);
temp_IMB_av = kcalloc(temp_IMB_cnt, sizeof(struct temp_av), GFP_KERNEL);
WGT_av = kcalloc(WGT_cnt, sizeof(struct addr_info), GFP_KERNEL);
[...]
ret = __second_parsing_ncp(session, &temp_IFM_av, &temp_OFM_av, &temp_IMB_av, &WGT_av);
First, the __pilot_parsing_ncp() function is used to count all the input, output, intermediate feature map descriptors and weight structures within the shared memory. After that, memory is reserved for them from the kernel heap. Finally __second_parsing_ncp() iterates over the same data and extract values into the freshly allocated structures. Let’s take a closer look at that:
int __second_parsing_ncp(
struct npu_session *session,
struct temp_av **temp_IFM_av, struct temp_av **temp_OFM_av,
struct temp_av **temp_IMB_av, struct addr_info **WGT_av)
{
[...]
// [1]
ncp_vaddr = (char *)session->ncp_mem_buf->vaddr;
ncp_daddr = session->ncp_mem_buf->daddr;
ncp = (struct ncp_header *)ncp_vaddr;
address_vector_offset = ncp->address_vector_offset;
address_vector_cnt = ncp->address_vector_cnt;
session->ncp_info.address_vector_cnt = address_vector_cnt;
memory_vector_offset = ncp->memory_vector_offset;
// [2]
memory_vector_cnt = ncp->memory_vector_cnt;
mv = (struct memory_vector *)(ncp_vaddr + memory_vector_offset);
av = (struct address_vector *)(ncp_vaddr + address_vector_offset);
[...]
for (i = 0; i < memory_vector_cnt; i++) {
u32 memory_type = (mv + i)->type;
u32 address_vector_index;
u32 weight_offset;
switch (memory_type) {
case MEMORY_TYPE_IN_FMAP:
{
// [3]
address_vector_index = (mv + i)->address_vector_index;
if (!EVER_FIND_FM(IFM_cnt, *temp_IFM_av, address_vector_index)) {
(*temp_IFM_av + (*IFM_cnt))->index = address_vector_index;
(*temp_IFM_av + (*IFM_cnt))->size = (av + address_vector_index)->size;
(*temp_IFM_av + (*IFM_cnt))->pixel_format = (mv + i)->pixel_format;
(*temp_IFM_av + (*IFM_cnt))->width = (mv + i)->width;
(*temp_IFM_av + (*IFM_cnt))->height = (mv + i)->height;
(*temp_IFM_av + (*IFM_cnt))->channels = (mv + i)->channels;
(mv + i)->stride = 0;
(*temp_IFM_av + (*IFM_cnt))->stride = (mv + i)->stride;
[...]
(*IFM_cnt)++;
}
break;
}
case MEMORY_TYPE_OT_FMAP:
{
[...]
}
case MEMORY_TYPE_IM_FMAP:
{
[...]
}
case MEMORY_TYPE_CUCODE:
case MEMORY_TYPE_WEIGHT:
case MEMORY_TYPE_WMASK:
{
// update address vector, m_addr with ncp_alloc_daddr + offset
address_vector_index = (mv + i)->address_vector_index;
// [4]
weight_offset = (av + address_vector_index)->m_addr;
if (weight_offset > (u32)session->ncp_mem_buf->size) {
ret = -EINVAL;
npu_uerr("weight_offset is invalid, offset(0x%x), ncp_daddr(0x%x)\n",
session, (u32)weight_offset, (u32)session->ncp_mem_buf->size);
goto p_err;
}
// [5]
(av + address_vector_index)->m_addr = weight_offset + ncp_daddr;
(*WGT_av + (*WGT_cnt))->av_index = address_vector_index;
(*WGT_av + (*WGT_cnt))->size = (av + address_vector_index)->size;
(*WGT_av + (*WGT_cnt))->daddr = weight_offset + ncp_daddr;
(*WGT_av + (*WGT_cnt))->vaddr = weight_offset + ncp_vaddr;
(*WGT_av + (*WGT_cnt))->memory_type = memory_type;
[...]
(*WGT_cnt)++;
break;
}
default:
break;
}
}
session->IOFM_cnt = (*IFM_cnt) + (*OFM_cnt);
return ret;
p_err:
return ret;
}
The pointer retrieved at [1] is the kernel virtual address of the shared ION buffer. The number of feature maps and weights is read again from the shared memory at [2] and then they are processed. The different types of feature maps are marshalled into the previously allocated struct temp_av arrays, just like at [3]. Meanwhile the weight structures are extracted into the struct addr_info array at [4]. I will refer to these descriptors together as memory vectors from now on like the code does.
There are at least two exploitable issues within the presented code. The address_vector_index, read from the ION buffer at [4], is not bound checked and used as an offset into the same buffer. The value at the offset is incremented with the bus address (physical address) of the ION buffer at [5], resulting in an out of bounds write primitive. Internally, the ION subsystem implements the DMA Buffer Sharing API and the dma_buf_vmap() function is used to assign kernel virtual addresses for ION buffers. After multiple indirections, the ion_heap_map_kernel() calls vmap() to map the buffer pages to a contiguous virtual address range. Vmap uses the same __get_vm_area_node() function as vmalloc to reserve kernel virtual addresses. As a result this bug can be leveraged to corrupt kernel memory allocated with vmalloc or mapped with vmap. Both Brandon Azad and aSiagaming rely on this primitive in their exploits.
The other vulnerability is a direct result of the shared nature of the ION buffer. Remember that in __pilot_parsing_ncp(), the different memory vectors are counted and kernel heap allocations are made based on the result. However, in __second_parsing_ncp() the number of descriptors is read again ([2]) from the shared memory and the kernel heap arrays are filled based on that value. This creates a TOCTOU race window where the count used for the allocation can be different from the count used to fill the buffers, potentially causing a kmalloc overflow. The rest of this blog post discusses how to exploit this vulnerability.
At the time of research the /dev/vertex10 device was readable by every user on the system and it had a very relaxed selinux permission set. Even untrusted applications were allowed to issue ioctl calls to this device. After the vulnerability was reported, Samsung restricted selinux access to platform apps and the camera server.
Research Setup
Since the vulnerability is in a kernel driver of a complex proprietary device, virtualization did not seem a practical approach for exploit development. Even though the number of steps and data wipes required increases with each model, Samsung phones are still shipped with an option to enable bootloader unlocking. After turning the phone towards Seoul and humming the Samsung notification sound backwards (or a series of similarly obscure steps) the OEM Unlock option appears in the developer menu. Samsung also releases the kernel sources for each firmware version. These can be built and flashed onto the devices, once the bootloader is unlocked.
In my experience heap exploit development often requires deeper insight into the inner workings of the allocator than what is provided by the kernel logs. Even though Linux provides very flexible and extensive tracing APIs I opted to simply patch the kernel to instrument the __kmalloc and kfree functions. The patches enable tracing allocations from selected kmalloc caches or allocations made by a selected process. I wrote a QT application to visualize these traces, the figures in this blog post about the heap layouts are extracted from this tool. The X axis represents the spatial domain and the Y axis represents the time domain, growing down. Each row captures the state of the heap (or part of it) at a given time, while columns describe whether a selected object is allocated or not over the course of time. Generally, colored boxes are allocated objects, the grey ones are freed objects while the dashed objects signal an unknown state, where no event was observed for the specific slot before. The red border is used to highlight the current event in the row.
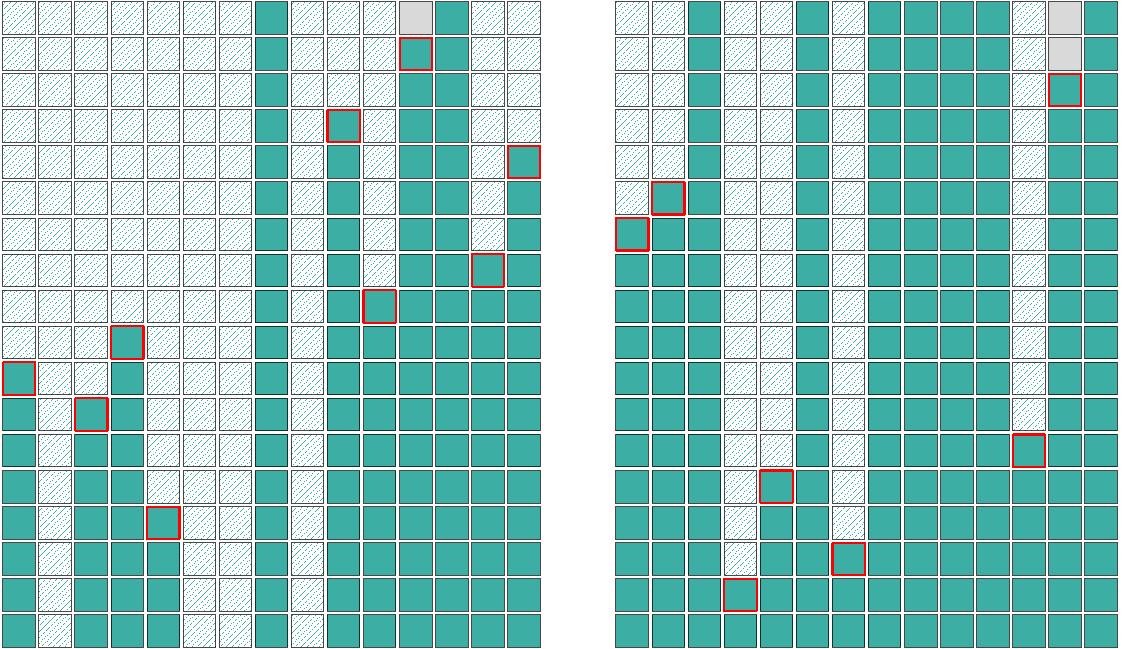
During the PoC development I used a Galaxy S10 with a rooted and instrumented kernel and a pristine Galaxy S20 to verify steps from application context. The bugs were the same on both models and the techniques I used worked on both devices.
Initial Primitive
Before going any further let’s explore the race condition and the kmalloc overflow a bit deeper. The root cause of the overflow is the fact, that the number of memory vectors is read first for the allocation, and then read again from shared memory during processing. While there is no synchronization event observable by user space between these two events, it is still a fairly trivial race to win. By continuously alternating two X and Y values, where X < Y, used as memory vector count, the race can be reliably won. The following scenarios can occur:
- Y is used for allocation and X or Y is used for copy
- X is used for allocation and X is used for copy
- X is used for allocation and Y is used for copy
The first scenario is the most simple as the allocation would land in a larger cache than the victim, there is no memory corruption or side effect. The second scenario causes an allocation in the same cache where the victim is, but there is no overflow. If the memory vectors are one of the feature map types, the allocation is immediately released causing no side effect. If they are weight types the allocation is not released, filling up a slot in the target cache, but no corruption occurs. This is still a minor side effect that would not prevent further retries. The third case is the ideal scenario when the allocation size is smaller than the copy size, so the overflow is triggered. As a result if the race is not won it can be attempted again, arbitrary times.
Now that it is established that the overflow can happen, let’s take a closer look at what is actually written. If the memory vectors are feature map type, they are unpacked into struct temp_av structures (at [3] in the previous listing). Whereas if the type is a weight type they are marshalled into struct addr_info structures (at [5]). These structures both differ in size and layout, in both cases only a limited set of fields are controlled.
The struct temp_av is 64 bytes, with the following fields:
offset - size - name
0 - 4 - index : Semi controlled, values are restricted
4 - 4 - hole : Untouched (compiler gap)
8 - 8 - size : Least significant 4 bytes are controlled, rest is zeroed
16 - 4 - memory_type: Untouched
20 - 4 - hole : Untouched (compiler gap)
24 - 8 - vaddr: Untouched
32 - 8 - daddr: Untouched
40 - 4 - pixelf_format: Controlled
44 - 4 - width: Controlled
48 - 4 - hieght: Controlled
52 - 4 - channels: Controlled
56 - 4 - strize: Zeroed
60 - 4 - cstride: Untouched
The struct addr_info is 56 bytes, with the following fields:
offset - size - name
0 - 4 - memory_type : Zeroed
4 - 4 - av_index : Semi controlled, values are restricted
8 - 8 - vaddr : Kernel pointer into the ION buffer at controlled offset
16 - 8 - daddr : Bus address of the ION buffer at controlled offset
24 - 8 - size : Least significant 4 bytes are controlled, rest is zeroed
32 - 4 - pixelf_format: Untouched
36 - 4 - width: Untouched
40 - 4 - hieght: Untouched
44 - 4 - channels: Untouched
48 - 4 - strize: Untouched
52 - 4 - cstride: Untouched
While neither of these layouts are ideal, as they contain uncontrolled fields and unchanged holes, they both provide interesting primitives. The temp_av structure has a 16 byte region where data is fully controlled and addr_info contains a kernel pointer into the shared ION buffer.
The overflown heap buffer is allocated to hold an array of one of these structures and the size of it can be chosen. The number of overflown elements can also be arbitrary.
Heap Feng Shui
Due to the size constraints of this publication I will refrain from discussing the kmalloc allocator in detail, except for a brief introduction of terminology. For the interested reader there are plenty of resources documenting the SLUB allocator (1, 2, 3, 4, 5) and even more on exploitation techniques (1, 2, 3, 4, 5, 6, 7). SLUB is the default allocator used by kmalloc on modern Android phones. It is a slot based allocator, where general allocation requests are rounded up to the next power of 2 size and allocated from the appropriate caches. Some of the more frequently used structures have their own dedicated caches. Each cache can hold multiple slabs which are contiguous sets of pages containing the allocated or freed objects (slots). In partial slabs (where free and allocated objects are mixed), the free objects are tracked by a single linked, inline freelist.
The main difference between Samsung and other Android devices is that on Samsung the smallest general kmalloc cache is 128 bytes. Further caches increase in size as power of 2 (256, 512, 1024, 2048, 4096, 8192). Since the memory vector arrays are allocated from the general cache and the allocation size is controlled, it is possible to target any of these caches.
Generally when exploiting heap overflows we want to create a layout where the victim object is preceded by a suitable free slot, that can be claimed by the overflow object. To increase the reliability of the exploit it is better to have a checkered layout where such free slots and victim objects alternate.
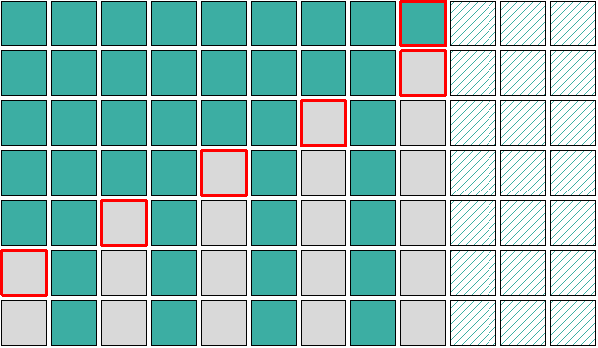
Visualization of the checkered layout. Green boxes represent allocated objects, while the grey ones are freed.
This way sporadic, random allocations would not prevent a successful overwrite of the victim object. Samsung kernels on the S10 and S20 are compiled with CONFIG_SLAB_FREELIST_RANDOM disabled, without freelist randomization the order of allocations is deterministic. To achieve this checkered layout a victim object is required that can be allocated multiple times, can also be individually released on demand (lifetime is controlled), and the allocation should be free of side effects in the given cache. Since the overflow primitive already puts a lot of constraints on the victim object it is better to use a separate object for heap shaping. The same layout can be achieved by first spraying the shaping object, then releasing every second one to spray the victim objects and finally releasing the rest of the shaping objects.

Visualization of the victim spraying. Green boxes represent the shaping object, the yellow ones are the victim object and the red one is the overflow object.
While it is possible to target any of the general kmalloc caches they are not all equally suitable for exploitation. According to my observations the smallest kmalloc-128 cache is very noisy, it is used very frequently even on an idle system. Large bursts of allocations are frequent which would make reliable exploitation harder. On the other end, large object sizes make intra slab overflows less likely. The overflow object is more likely to end up at the end of slab overwriting different slabs or unrelated pages. This issue can be mitigated by sufficient amount of spraying, but it won’t be completely eliminated.
To summarize, this exploit approach would require two different objects that satisfy the following conditions:
A shaping object:
- Can be allocated arbitrary number of times
- Side effect free (does not cause further allocations or frees) in the target cache
- Can be freed on demand
- Available on the Galaxy kernel and can be triggered from untrusted application context
A victim object:
- Has an interesting field that overlaps with a controlled field of the overflow structures
- There are no fields in it that would be corrupted by the uncontrolled overflow fields in a way that would prevent exploitation
- Resilient to Samsung specific protection features (RKP, debug linked lists)
- Lifetime is controlled or long enough that the overflow can happen and the overwritten field can be accessed
- Preferably can be allocated multiple times
- Preferably allocated from the kmalloc-256 or kmalloc-512 caches
- Available on the Galaxy kernel and can be triggered from untrusted application context
Shaping Object
In the proof of concept exploit I used the timerfd_ctx structure for heap shaping. It is allocated by the timerfd_create system call and satisfies all the required conditions. The number of objects that can be sprayed is only limited by ulimit, that restricts the number of file descriptors that can be opened by an application at the same time to 32768. This value is sufficiently large for our spraying requirements. The size of timerfd_ctx is 216 bytes so it is allocated from the kmalloc-256 cache and timerfd_create() causes no further allocations in this cache. The system call can be invoked by any process on the system (unless the process is in a seccomp jail), it has no explicit permission checks.
The allocated timerfd_ctx object can be freed by closing the associated file descriptor. The close system call does not release resources immediately, it simply decrements the reference counter for the file object and sets up a deferred work. This deferred task work should run in the same context as the original process but it might sleep or willingly give up CPU time. The issue with that is SLUB has per CPU freelists, if a kfree is executed on a different core than the consecutive allocations, they would be satisfied from a different slab. Obviously, this is undesirable as it could ruin the determinism of the allocation sequence. I found that this problem can be solved reliably by pinning the heap exploit thread to a CPU and by keeping other cores busy at the same time.
Victim Object
I spent a significant amount of time searching for a suitable victim object, mostly looking for a primitive to leak kernel data to break KASLR. The temp_av structure provides more control over the fields written so I was focusing mostly on that. I began by testing objects that were used in previous Linux LPE exploits, but they were either in subsystems not compiled on Android, not available from untrusted applications, or they have been extended with further hardening (struct iovec, struct cred). I continued by exploring the allocations made by the NPU driver, since I was already familiar with the code, however the uncontrolled overflow fields were causing crashes before any meaningful corruption could be triggered.
At the time of writing CodeQL was freshly released. CodeQL is a static analysis framework, designed to run various queries on large codebases. It has a clang based backend that supports C and C++ projects. I was curious to find out how this tool functions with a complex and large project such as the kernel, and whether I could write a query that assists in finding a victim candidate. I found that the setup was very straightforward and the queries were efficient, however the complex examples available at the time were limited. The query below lists all the kmalloc family allocations that have a fixed size, a size that falls into a selected range, and have a possible call chain to them from a system call handler or a struct file_operations callback.
import cpp
// Check if the function is set as a fielf of
// struct file_operations
predicate isFopsHandler(Function f) {
exists(Initializer i |
i.getDeclaration().(Variable).getUnspecifiedType().hasName("file_operations") and
f = i.getExpr().getAChild().(Access).getTarget())
}
// Can the function be called from system call handler
// or from a file_operations callback
predicate isSysHandler(Function f) {
f.getName().matches("sys_%")
or
isFopsHandler(f)
or
// Apply this recursively to previous functions in the control flow
isSysHandler(f.getACallToThisFunction().getControlFlowScope())
}
// Return the name of the calling function
string getSysHandler(Function f) {
(f.getName().matches("sys_%") and result = f.getName())
or
(isFopsHandler(f) and result = f.getName())
or
result = getSysHandler(f.getACallToThisFunction().getControlFlowScope())
}
from FunctionCall fc, Function f, string sys
where
// Match kmalloc family allocations
fc.getTarget().getName().regexpMatch("k[a-z]*alloc") and
// With a given size
(fc.getArgument(0).getValue().toInt() > 128 and fc.getArgument(0).getValue().toInt() <= 256) and
// Reachable from system call or file operation
isSysHandler(fc.getControlFlowScope()) and sys = getSysHandler(fc.getControlFlowScope())
select fc, "Callsite of fitting K*alloc: " + fc.getTarget().getName() + "(" + fc.getArgument(0).getValue().toString() + ") by " + fc.getControlFlowScope().getName() + " from " + sys
This query takes around 20 minutes to execute and provides a list of 50-60 victim candidates on the S10 and S20 kernels. It could be further optimized to include variable size allocations, where the size is potentially controlled by the user, or to include constraints on the allocated type. Overall I was satisfied with CodeQL, it found a series of structures that were used in previously published exploits (e.g. struct binder_transaction, struct seq_file) and some really promising new ones (struct ion_buffer). Unfortunately, they all had the same fundamental issue as previous candidates: the uncontrolled overflow fields would cause undesirable crashes around when the overwritten field was accessed. At this point I have decided to explore a different approach.
What is Old is New Again and Again and Again
As previously mentioned, the SLUB allocator maintains a single linked list of free objects within partial slabs. The address of the first free object is either retrieved from the per CPU cache or stored within the associated struct page descriptor. The pointers of consecutive list elements are stored inline, on the first 8 bytes, of the free objects. The kernel inherently trusts these values, when they are retrieved by get_freepointer() there are no sanity checks. These freelist pointers can be abused to smuggle in arbitrary objects, that would be returned during future allocations. This technique was already documented in 2009 and mitigations were suggested by Larry H in Linux Kernel Heap Tampering Detection.
In kernel version 4.14 the CONFIG_SLAB_FREELIST_HARDENED option was introduced in the upstream kernel. The goal of this patch was to prevent exactly these types of freelist overwrite attacks. This is achieved by XORing the pointer value with the pointer’s location and a per-cache random cookie, and storing the result in the free object. The kernels on Galaxy S10 and S20 are compiled without this hardening feature, enabling potential freelist poisoning attacks. The question remains if the overflow object can align with the freelist pointer in a way to control it.
The two overflow primitives provide two different ways to exploit this vulnerability. If the temp_av structure is used the freelist pointer could potentially be overwritten with a fully controlled value. However, we would first need to construct some KASLR leak to use this. The addr_info structure, however, contains a kernel pointer into the shared ION memory. This pointer is filled by the kernel when the structure is initialized during the overflow ([8]). If this field would overlap with a freelist pointer, a consecutive allocation would return memory from the shared buffer. This would be an extremely strong primitive as it would allow unlimited read/write access to the kmalloc allocated object from user space while defeating KASLR as well (i.e. we don’t need to figure out the kernel VA of the shared ION memory ourselves in order to hijack the kmalloc allocation into it).
int __second_parsing_ncp(
struct npu_session *session,
struct temp_av **temp_IFM_av, struct temp_av **temp_OFM_av,
struct temp_av **temp_IMB_av, struct addr_info **WGT_av)
{
[...]
// [6]
ncp_vaddr = (char *)session->ncp_mem_buf->vaddr;
[...]
case MEMORY_TYPE_CUCODE:
case MEMORY_TYPE_WEIGHT:
case MEMORY_TYPE_WMASK:
{
// update address vector, m_addr with ncp_alloc_daddr + offset
address_vector_index = (mv + i)->address_vector_index;
// [7]
weight_offset = (av + address_vector_index)->m_addr;
[...]
// [8]
(*WGT_av + (*WGT_cnt))->vaddr = weight_offset + ncp_vaddr;
The weight_offset can be adjusted ([7]) to control the exact location of the allocation within the shared memory buffer. The vaddr field is at an 8 byte offset in the addr_info structure, so a cache size and count pair is needed for which the following can be satisfied:
$$n \times cache\_size \equiv 8 \pmod{56}$$The kmalloc-512 cache with n = 1 and the kmalloc-256 cache with n = 2 satisfy these constraints. In other words, the vaddr field of 10th element of an addr_info array would overlap a freelist pointer in these caches, as it falls at a 512 byte offset.
I found that the most reliable way to overflow this pointer was to use the kmalloc-256 cache and forgo any advanced heap shaping. If the overflow allocation lands in a cache that has at least two free objects after it, the vaddr field overlaps the free pointer in the second object. Luckily at offset 32 within addr_info there is a hole, that is not touched, so the freelist pointer in the first object is not corrupted (256 % 56 = 32). The only problem is when the overflow object lands at the end of the slab and corrupts something unintentional, but the chances of that can be minimized by sufficient amount of spraying.
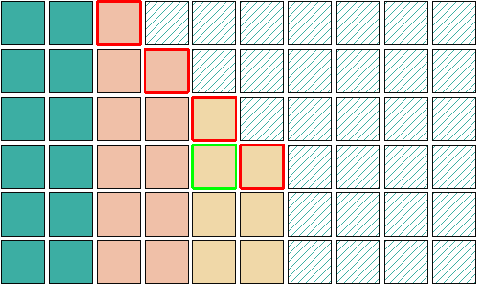
Visualization of successful freelist poisoning. The red objects are used for the overflow then the yellow victim objects are allocated. The third victim lands in the shared memory, due to the corrupted free list.
Not All Memory Created Equal
The freelist overwrite allows an arbitrary object from the kmalloc-256 or kmalloc-512 caches to be allocated in the shared memory, providing complete control over it. The only question that remains is which object to use to create a convenient arbitrary read write primitive.
Initially I tried to utilise the seq_file structure. It is created in seq_open() when a file is opened from the procfs virtual file system. By controlling this structure, and the content of the opened file, seq_read() can be leveraged to achieve both arbitrary read and write. The content of some procfs files, such as /proc/self/comm, can always be written by the owner process. The seq_file structure has a buf pointer that serves as an intermediate buffer between user space and the file. Depending on the request size and read position (stored in the same structure), the buffer is either just copied to user space, or filled in by the file specific show() callback. In case of /proc/self/comm this callback (comm_show()) simply copies the processes comm string to the buffer, which can be set by writing the same file.
This could be the ideal structure to finish the exploit, however there is just one obstacle. Remember that the ION buffer is shared with the device, so it is either outer shared or system shared memory. When executing an atomic instruction in this memory (e.g. ldadd) a bus fault is generated and the kernel panics. I could not find the root cause of this behavior in the ARM documentation. It is specified that if the atomic operation misses all the caches in the system (including L3) and CHI (Coherent Hub Interface) is used, the request is sent out to the interconnect to perform the operation. I suspect this is the case here, but I don’t know what is supposed to happen if the interconnect cannot ensure coherency or fails to carry out the operation. These atomic instructions are used when implementing reference counting or locking in the Linux kernel. As a result, structures that contain such fields cannot be used in the shared memory.
While reviewing the code in fs/pipe.c for the iovec overwrite attempt, I took a notice of the struct pipe_buffer array. When the pipe is created an array of pipe_buffer-s is allocated from the kernel heap, containing a structure for each buffer page belonging to the pipe. Let’s take a closer look how this structure is defined and used.
struct pipe_buffer {
struct page * page; /* 0 8 */
unsigned int offset; /* 8 4 */
unsigned int len; /* 12 4 */
const struct pipe_buf_operations * ops; /* 16 8 */
unsigned int flags; /* 24 4 */
/* XXX 4 bytes hole*/
long unsigned int private; /* 32 8 */
/* size: 40, cachelines: 1, members: 6 */
};
The page field is a pointer to the vmemmap array entry, that represents the page that is allocated for the pipe buffer (with alloc_page()). The offset and len fields are used to determine whether there is enough data or free space within the buffer to satisfy a read or write request. In pipe_write(), data from user space is written to the pointed page, if there is enough room, while pipe_read() returns data to user space from the page. Both of these functions map the selected page into kernel virtual memory if it is not already. By controlling the page, offset and len fields it is possible to read and write arbitrary data within arbitrary pages.
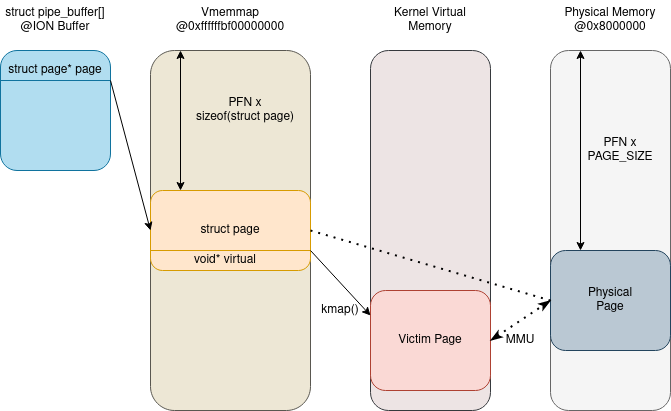
Connection between vmemmap and the physical and virtual memory
To understand the exact consequences of this we need to explore the vmemmap array and the kernel physical memory management a bit deeper. Vmemmap is a virtual mapping of all memory maps, basically a virtually contiguous struct page array, where each physical memory page is represented by an array entry. The struct page belonging to the N-th physical page is located at vmemmap[N - 1]. The purpose of this is to make PFN (Page Frame Number) conversion to and from struct page easy and efficient. Sections of the physical memory address space, that are not managed by kernel, are simply not mapped in this array. Since linear kernel memory addresses are not randomized on Samsung kernels, the virtual address of this array is constant. On ARM64 architecture any page can be read or written through this primitive, that is accessible for the kernel, if the PFN number for the page is known.
Translating any linear address (including kernel heap addresses) to the corresponding PFN number is trivial, it is done by applying a constant offset and then dividing by the page size. The PFN of the base image of the kernel can be found by searching the memory, from the beginning, for the kernel magic. This process is very fast, as the physical memory KASLR is fairly limited, only a couple of pages need to be accessed. Once the base image and global page table is found, any kernel virtual address can be translated to a PFN number. As a result, the pipe_buffer control allows arbitrary access to any physical page, managed by the kernel, including pages of user space application swapped into physical memory. The only limitation is that the read only parts of the kernel image cannot be patched, as they are also mapped read only in the linear address space. When the pages are mapped for access their linear kernel address is returned.
The ops field of the pipe_buffer can be used to redirect control flow to achieve actual kernel code execution if someone has those kind of fetishes.
My proof of concept exploit first preallocates the pipe with the default number of 16 buffer pages. Then it sprays the heap with timerfd_create to fill up any holes in the kmalloc-256 cache. It triggers the race condition multiple times while trying to allocate 4 memory vector and overflow with 10. Then the F_SETPIPE_SZ fcntl is called on the pipe with the size of 4 pages. This causes the pipe_buffer array to be reallocated in the target cache (40x4=160), ideally this allocation lands in the shared memory. If the overflow was not successful it can be reattempted after a bit more spraying. Once the pipe_buffer is controlled it can be used to read or write any pages based on the PFN number. The PoC scans the memory for the kernel magic, locates the kernel base image and overwrites the kernel version info string.
Demo
Here is a video demo of the exploit in action on an S10!
Closing Thoughts
In this blog post I detailed how a kernel heap overflow can be exploited on a modern Android device. While there is strong access control (selinux) that significantly reduces the available objects to untrusted applications and there are mitigations to protect certain kernel structures (RKP, debug linked lists, iovec hardening), the kernel is still large and complex enough to provide suitable objects for exploitation. As demonstrated in this article it is still possible to reliably exploit even a suboptimal heap overflow where the overflown data is only partially controlled.