Samsung’s neural processing framework has received a lot of attention from the security community since its introduction. Hardware isolation vulnerabilities have been demonstrated, both on the NPU and DSP cores (1, 2), that could be used to compromise the kernel. The surrounding kernel code was also exploited by multiple researchers to gain local privilege escalation (1, 2). I, too, explored in a previous blog post how a kmalloc overflow within the Samsung NPU kernel driver can be exploited to gain arbitrary kernel read/write access. As a follow up work, I’ve decided to investigate Huawei’s implementation of their neural processing framework. Despite being the second largest vendor on the Android market, recently there have been lot fewer technical papers published about the security of their devices.
In this blog post I will briefly compare the architecture of the two frameworks from an application’s point of view. I will introduce the bugs I found within the Huawei NPU kernel driver, and the methods I used to exploit them, to gain arbitrary read-write kernel access. I will be focusing on the differences between the security posture of modern Huawei and Samsung kernels, with an emphasis on features that aim to prevent exploitation.
Neural Processing Subsystems
Huawei phones are shipped with a dedicated NPU (Neural-network Processing Unit) core since the Kirin 980 SoC. The NPU is part of the HiAI Mobile Computing Platform that allows developers to efficiently compute neural network operations based on offline models. The concepts are very similar to Samsung’s Neural SDK, however there are notable differences between the two subsystems’ architectures.
The Samsung NPU kernel driver was originally accessible to every application and their SDK directly used it to upload and operate on network models.
Last year, in the November update, the access to the /dev/vertex10 NPU device was restricted to platform applications and the SDK is no longer available to third party developers.
While the NPU has been restricted, the /dev/dsp device is still exposed to all untrusted applications and it was possible to upload arbitrary models and code until certain ioctls were removed in the February 2021 update.
I am not aware of any publicly available libraries that utilize the DSP core and I don’t know how much of the original functionality is retained after the removal of these ioctl handlers.
On Huawei phones, the /dev/davinci0 and /dev/davinci_manager devices are present to interact with the NPU kernel driver.
The access to these devices is restricted by selinux, and the hiaiserver system service is the only one that can operate on them.
The hiaserver service exposes a series of binder APIs that allows network models to be uploaded and executed on the NPU core.
These binder APIs are implemented by a client library that is available to application developers.
Untrusted applications must rely on these binder APIs to access the features of the subsystem.
The research introduced in this article focuses on the NPU’s kernel driver implementation. The audit and the exploitation of the hiaiserver is not discussed for now.
I will assume that the hiaiserver can be compromised through its binder APIs and the PoC can execute within its context.
This is a strong assumption and a very significant difference compared to the Samsung research.
(While we are on the topic of introducing Huawei’s Da Vinci core - did you know that Da Vinci himself has famously suffered a nerve damage episode that has actually limited his abilities to paint, going as far as being a cause for leaving some of his most famous works like the Mona Lisa supposedly unfinished? I didn’t - but the BBC says so, so it must be true. Talk about hitting a nerve…)
Research Setup
Huawei only releases the source code of their kernels upon major version changes, and the source code might lag behind the up-to-date image version in terms of security updates. Nevertheless, the released sources can be modified and built. Once the bootloader is opened up to disable image verification, a custom compiled kernel can be flashed onto the device and booted.
In customizing my research kernel, I have installed the same kmalloc tracer that I used for the Samsung NPU research and instrumented the kernel to facilitate debugging and exploit development. The research was carried out on a P40 Pro (firmware version 10.1.0.176), however all devices with Kirin 980 and Kirin 990 chipsets should have been similarly affected. The final proof-of-concept exploit was verified on the original kernel image.
There is a “slight” issue here with unlocking bootloaders, however. Samsung is a convenient research platform as it supports bootloader unlocking and the flashing of modified kernels. Huawei, on the other hand, stopped providing bootloader unlock codes in 2017 and there is no official way to install altered kernel images on more recent devices. This meant that we needed to find a way to defeat Huawei’s secure boot. See the next section on a brief background on this.
Detour: Huawei Bootrom Exploitation
Over the course of the last year, together with my colleagues, Daniel Komaromy and Lorant Szabo, we have carried out extensive research into Huawei Kirin basebands. Much like with the kernel, our baseband vulnerability research has also eventually ran into the challenge of Huawei’s secure boot limitations.
Luckily, Lorant and Daniel have identified several bootloader vulnerabilities, some in the second stage bootloader and some in the bootrom code itself. In May 2020, we have sent Huawei several reports describing in total six different exploit chains, all of which gained full code execution at the EL3 level, providing full secure boot bypasses and therefore complete control of the SoC. All told, we have written exploits for 970, 980, 990 Kirin chipsets.
After a year, we have submitted our research white paper to Black Hat. Following the acceptance and the announcement of the talk, we did some more research and identified an additional exploitable vulnerability in bootrom code that is separate (found in a different layer of the bootloader stack) from those in the BH submission.
By this time, Huawei has published fixes for our non-bootrom bootloader vulnerabilities months ago. On the other hand, bootrom vulnerabilities are typically assumed “unfixable” - as seen in some infamous examples such as the “checkm8” iPhone bootrom vulnerability. Quite interestingly, following long discussions, Huawei actually identified a way to mitigate the bootrom vulnerabilities as well and published OTA updates for Kirin 990 devices at the end of last month! We want to give a shout-out to Huawei here for a bit of engineering ingenuity in creating a mitigation for bootrom issues as well as for the courage to go for a relatively high risk patch. Their commitment to finding a technical (as opposed to a legal) solution was refreshing to see.
After another month of delay, we are now disclosing the additional bootrom vulnerability that we have identified and reported to Huawei this May.
The advisory contains a brief summary of the vulnerability in the Huawei bootrom’s USB stack. For all additional context regarding our secure boot research (the reverse engineered details of the Huawei secure boot chain, all of our other bootloader vulnerabilities, explanations on how to exploit them for code execution, completing exploitation to gain full control of the device e.g. loading patched kernel images, etc) together with our research into remote baseband exploitation and sandbox escapes from the baseband to the Linux kernel and TrustZone - make sure to check out our presentation (and accompanying white paper) which will be released next week at Black Hat!
Final note: due to Covid reasons, the Black Hat presentation had to be recorded and finalized before we had the opportunity to analyze Huawei’s bootrom fix. Nonetheless, in the Q&A session of the talk, we’ll be able to get into details about Huawei’s final fixes as well - so make sure to join if you would have any questions about that :)
Everywhere I Go
During my initial code review I have discovered several bugs within the NPU driver code, including kernel structures disclosed in shared memory (CVE-2021-22389), an any call primitive (CVE-2021-22388), an oob write vmap write (CVE-2021-22412), a kmalloc double free (CVE-2021-22390), and a mmap overlap crash (CVE-2021-22415).
(All of these vulnerabilities have been included in Huawei’s June 2021 security update.)
The any call primitive is severely restricted by the Clang forward-edge CFI which is used by Huawei kernels.
It should also be mentioned, that Huawei uses a fairly strong memcpy_s implementation in their kernel.
It verifies the provided source and destination sizes even when they are dynamically calculated.
The verification check rejects unreasonably large sizes which negates the impact of many integer arithmetics-based under or overflows.
As a comparison the Galaxy S20 still uses Samsung’s homebrew CFI solution, where each function is preceded by a constant 4 byte tag. Function pointers are called through a stub that verifies the presence of these 4 byte markers before the called function. This ensures that functions are called at their beginning and hijacked function pointers cannot call into the middle of a function. Clang’s CFI provides much stronger guarantees, it classifies the functions based on types and ensures, that from each call site, only functions with matching type can be called. For a complete description check out the relevant llvm documentation.
Out of these bugs the shared kernel structures and the double free seemed to be the most promising for exploitation purposes. Let’s take a closer look at these.
The Huawei NPU driver implements a custom mmap interface in devdrv_npu_map.
Based on the provided offset, three different regions can be mapped by the function.
MAP_L2_BUFF: Maps the same “pad” physical page to user space as many times as requestedMAP_CONTIGUOUS_MEM: Physically contiguous memory, cannot be mapped directly from user spaceMAP_INFO_SQ_CQ_MEM: Maps four different, preallocated memory regions to user space indevdrv_info_sq_cq_mmap
static int devdrv_npu_map(struct file *filep, struct vm_area_struct *vma)
{
struct npu_vma_mmapping *npu_vma_map = NULL;
[...]
// [1]
npu_vma_map = (struct npu_vma_mmapping *)kzalloc (sizeof(struct npu_vma_mmapping), GFP_KERNEL);
COND_RETURN_ERROR(npu_vma_map == NULL, -EINVAL, "alloc npu_vma_map fail\n");
dev_id = proc_ctx->devid;
vm_pgoff = vma->vm_pgoff;
map_type = MAP_GET_TYPE(vm_pgoff);
mutex_lock(&proc_ctx->map_mutex);
NPU_DRV_WARN("map_type = %d memory mmap start. vm_pgoff=0x%lx, vm_start=0x%lx, vm_end=0x%lx\n",
map_type, vm_pgoff, vma->vm_start, vma->vm_end);
switch (map_type) {
case MAP_RESERVED:
ret = -EINVAL;
break;
case MAP_L2_BUFF:
ret = devdrv_map_l2_buff(filep, vma, dev_id);
list_add(&npu_vma_map->list, &proc_ctx->l2_vma_list);
break;
case MAP_CONTIGUOUS_MEM:
share_num = MAP_GET_SHARE_NUM(vm_pgoff);
ret = devdrv_map_cm(proc_ctx, vma, share_num, dev_id);
list_add(&npu_vma_map->list, &proc_ctx->cma_vma_list);
break;
case MAP_INFO_SQ_CQ_MEM:
// [2]
ret = devdrv_info_sq_cq_mmap(dev_id, filep, vma);
list_add(&npu_vma_map->list, &proc_ctx->sqcq_vma_list);
break;
default:
NPU_DRV_ERR("map_type is error\n");
ret = -EINVAL;
break;
}
npu_vma_map->map_type = map_type;
npu_vma_map->proc_ctx = proc_ctx;
npu_vma_map->vma = vma;
vma->vm_flags |= VM_DONTCOPY;
vma->vm_ops = &npu_vm_ops;
// [3]
vma->vm_private_data = (void *)npu_vma_map;
vma->vm_ops->open(vma);
mutex_unlock(&proc_ctx->map_mutex);
if (ret != 0)
NPU_DRV_ERR("map_type = %d memory mmap failed\n", map_type);
return ret;
}
Out of these, the third option is the most interesting, the layout of the mapped shared memory is the following:
|___SQ(32MB)___|____INFO(32MB)_____|__DOORBELL(32MB)___|___CQ(32MB)___|
The SQ (Submission Queue), CQ (Completion Queue) and doorbell regions are used to implement ring-buffers to send and receive data to and from the device. The info region however, contains structures that are used by the kernel to manage the device. These are inherently trusted by the kernel and some of them contain raw kernel pointers. The layout of the info memory is as follows:
| 64 * struct devdrv_ts_sq_info | 1 * struct devdrv_ts_cq_info | 2 * 64 * struct devdrv_stream_info |
This kernel memory can be mapped with read-write permissions from user space. Most of the device ioctls interact with these structures providing various kernel primitives. Exploring all of these would not be possible within the constraint of this article, I will only detail how I exploited one of the many resulting primitives.
The other equally strong vulnerability is the kmalloc double free within the same mmap interface.
Once the devdrv_npu_map function creates the requested mapping it sets up custom operations for the new virtual memory area (VMA).
The VMAs (struct vm_area_struct) are structures within the kernel to represent various memory mappings belonging to a process.
The vm_ops field can be set to a struct vm_operations_struct structure, so a device, that implements the mmap interface, can define custom actions for certain memory events.
This can be used to fault in pages, if specific parts of the mapping is accessed, or ensure synchronization with a backing device.
The NPU driver implements two of the custom handlers, the npu_vm_open simply logs when the VMA is created, and npu_vm_close is responsible for freeing up the allocated resources.
The devdrv_npu_map function kmalloc allocates a 48 byte npu_vma_mmapping structure at [1].
This is later saved in the vm_private_data field of the freshly initialized VMA at [2].
The interesting part happens in the close function:
void npu_vm_close(struct vm_area_struct *vma)
{
struct npu_vma_mmapping *npu_vma_map = NULL;
struct devdrv_proc_ctx *proc_ctx = NULL;
COND_RETURN_VOID(vma == NULL, "davinci munmap vma is null\n");
NPU_DRV_DEBUG("davinci munmap: vma=0x%lx, vm_start=0x%lx, vm_end=0x%lx\n",
vma, vma->vm_start, vma->vm_end);
npu_vma_map = (struct npu_vma_mmapping *)vma->vm_private_data;
COND_RETURN_VOID(npu_vma_map == NULL, "davinci mmap npu_vma_map is null\n");
proc_ctx = (struct devdrv_proc_ctx *)npu_vma_map->proc_ctx;
COND_RETURN_VOID(proc_ctx == NULL, "proc_ctx is null\n");
if(npu_vma_map->map_type > MAP_RESERVED && npu_vma_map->map_type < MAP_MAX) {
mutex_lock(&proc_ctx->map_mutex);
list_del (&npu_vma_map->list);
mutex_unlock(&proc_ctx->map_mutex);
}
// [4]
kfree(npu_vma_map);
vma->vm_private_data = NULL;
}
Whenever npu_vm_close is called the content of the vm_private_data field is kfreed and the field is cleared ([4]).
This behaviour is based on the assumption that virtual memory areas are immutable and the close operation can only be triggered once.
In practice this is not the case, when virtual memory mapping is split a new VMA is created and the fields of the original are copied to it.
The start and end addresses and size of both VMAs are adjusted to reflect the state after the split.
This happens, for example, when part of a memory mapping is unmapped.
The kernel first copies and splits the original VMA and calls the close callback only on the part that is being unmapped.
As a result it is possible to force a kfree on the same kernel virtual address arbitrary times by unmapping the mmapped device memory page by page.
This can be turned into a use-after-free against any chosen victim that is allocated from the general kmalloc-64 cache.
List of Hardenings, Hardening of Lists
Throughout the last couple of years there has been an abundance of kernel LPE publications that feature kmalloc double-frees and use-after-frees (1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, …). There are well documented techniques, victim structures, spray and overwrite primitives that can be used to build such exploits. Initially, I started working on the shared structure vulnerability as I found it the more interesting bug. However, Huawei rated the double-free vulnerability the least impactful out of the reported bugs, which led me to believe there might be some exciting mitigations that prevent the exploitation of this vulnerability class on Huawei devices. As it turns out there is no such thing, regardless it was a good opportunity to compare the heap hardening features of the two vendor kernels.
As discussed in my previous post, the Galaxy S20 kernel was built without CONFIG_SLAB_FREELIST_HARDENED enabled.
This hardening feature protects the freelist pointers, that are stored within the freed heap objects, by XORing the list pointer with a cache specific, random value and the address of the free object.
On Huawei this kernel configuration is turned on, preventing kmalloc use-after-frees and overflows to hijack the freelist pointer and force allocations from controlled locations.
Unlike Samsung, Huawei also enables the CONFIG_SLAB_FREELIST_RANDOM hardening feature.
As the name suggests, this randomizes the order in which objects are inserted into the freelist within a slab.
As a result subsequent allocations are not necessarily consecutive in memory, instead they are random within the slab pages.
This can provide a probabilistic mitigation against kmalloc overflows, where the effectiveness depends on the cache size.
However, it does not provide much protection against our double free primitive as both the victim and the overflow object can be sprayed until the freed object is reclaimed.

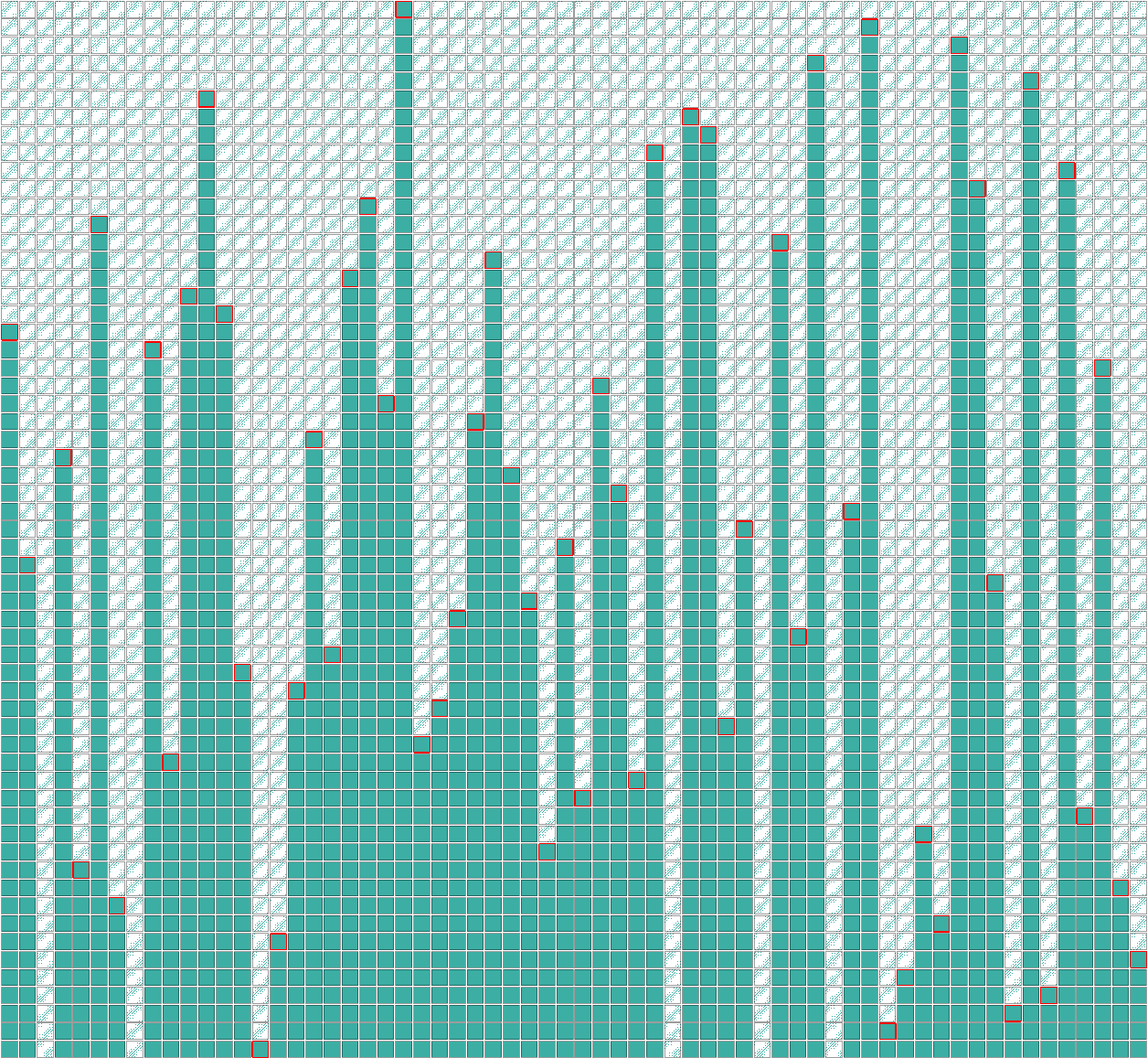
The figure above shows the traces of consecutive allocations without freelist randomized, while the second figure shows them when the mitigation is enabled
The only Huawei specific heap mitigations I have encountered, are the CONFIG_HW_SLUB_DF and CONFIG_HW_SLUB_SANITIZE features.
These provide a double free detection by tagging freed objects with a random canary.
This can detect if a freed object is released again, however if the object is reclaimed by an allocation and freed again through a dangling pointer this protection is ineffective.
I consider this more of a debugging than a mitigation option.
I used the multiple-free primitive to overwrite a chosen object within the kmalloc-64 cache.
The steps to achieve this are as straight forward as it gets.
- Open the
/dev/davinci0device and mmap at least three pages of it - munmap the first pages causing the original
struct npu_vma_mmappingobject to be freed, while retaining the dangling pointer - Spray the selected victim object which should reclaim the freed slot within the slab
- munmap the second mapped page, causing the victim object to be freed through the dangling pointer
- Spray controlled data with the usual
send[m]msgtechnique to overwrite the victim object
I implemented this and found that I was able to overwrite the victim reliably.
The only additional trick required was to pin the main thread and the spraying threads on the same CPU core by the sched_setaffinity syscall.
Otherwise the per-CPU freelists could prevent the released object to be reclaimed by the sprayed objects.
This was not an issue as the hiaiserver selinux context has setsched permission and it is able to set its affinity mask.
To complete the exploit using this bug is left as an exercise for the reader, along with the hiaiserver exploit of course :)
Exploiting NPU Shared Memory
Going back to shared kernel memory, let’s take a closer look at the structures that are mmapped to user space and how they are used by the kernel.
The NPU kernel device relies on so called streams to manage input and output data flows.
These streams can be allocated and released through the devdrv_ioctl_alloc_stream() and devdrv_ioctl_free_stream() ioctls.
At the same time, there can only be 64 sink and 64 non-sink streams allocated at most.
For each potential stream a struct devdrv_stream_info is reserved in the shared “info” memory region.
| 64 * struct devdrv_ts_sq_info | 1 * struct devdrv_ts_cq_info | 2 * 64 * struct devdrv_stream_info |
These structures are globally assigned to the various clients, who use the device, and they are pre-initialized upon device probe by the devdrv_stream_list_init() function.
Whenever a new stream is allocated by the alloc stream ioctl, the next free stream info is reserved for the new stream, and the associated stream id is returned.
struct devdrv_stream_info {
int id;
u32 devid;
u32 cq_index;
u32 sq_index;
void *stream_sub; // points to a struct devdrv_stream_sub_info
int pid;
u32 strategy;
u16 smmu_substream_id;
u8 priority;
u8 resv[5];
};
For each of these stream info structures there is an associated struct devdrv_stream_sub_info structure pointed by the stream_sub field.
These sub info structures are also initialised upon device probe and they reside within a large vmalloc buffer.
Before moving on to the actual exploitation it is crucial to understand how these structures are used and managed by the kernel driver.
struct devdrv_stream_sub_info {
u32 id;
struct list_head list;
void *proc_ctx;
};
The sub info is basically a linked list node and it is used to account for the free and allocated streams. There is a global list of free streams and a per-process list of allocated streams. The per-process list is used to clean up after a process, that failed to release all of its allocated resources.
When a client process calls the alloc stream ioctl the following chain of calls is executed.
First devdrv_ioctl_alloc_stream() receives the parameters from user space, then devdrv_proc_alloc_stream() calls devdrv_alloc_stream() ([5]) to retrieve a pointer to the next free stream info structure.
Inside the devdrv_alloc_stream() calls devdrv_alloc_(non_)sink_stream_id() which walks the global free sub info list and removes the first node.
Note that the struct devdrv_stream_sub_info does not have a back-pointer to its stream info, instead it has an id field.
Once the id is allocated devdrv_calc_stream_info() is used to find the address of the stream info for the given id, within the “info” memory.
int devdrv_proc_alloc_stream(struct devdrv_proc_ctx *proc_ctx, u32 *stream_id, u32 strategy)
{
struct devdrv_stream_info* stream_info = NULL;
struct devdrv_stream_sub_info *stream_sub_info = NULL;
[...]
// [5]
stream_info = devdrv_alloc_stream(stream_cq_id, strategy);
stream_info->pid = proc_ctx->pid;
// [6]
stream_sub_info = (struct devdrv_stream_sub_info *)stream_info->stream_sub;
if (strategy == STREAM_STRATEGY_SINK) {
// [7]
list_add(&stream_sub_info->list, &proc_ctx->sink_stream_list);
proc_ctx->sink_stream_num++;
} else {
// [7]
list_add(&stream_sub_info->list, &proc_ctx->stream_list);
proc_ctx->stream_num++;
}
NPU_DRV_DEBUG("npu process_id = %d thread_id %d own sink stream num = %d, non sink stream num = %d now \n",
proc_ctx->pid, current->pid, proc_ctx->sink_stream_num, proc_ctx->stream_num);
*stream_id = (u32)stream_info->id;
return 0;
}
In devdrv_proc_alloc_stream() once the stream info is retrieved its stream_sub field is accessed ([6]) to obtain a pointer to the associated sub info structure.
This is supposed to point to the same sub info that was just unlinked from the global free list, however, as the stream info resides in the shared memory, it can be corrupted by the user space application.
The newly retrieved sub info is added back to the process specific allocated stream list at [7].
At this point it is possible to control the stream_sub pointer of a selected stream info structure, through the user space “info” mapping.
If alloc stream is called on the corrupted stream the hijacked sub info is linked into the allocated stream list.
The NPU driver also implements the DEVDRV_IOC_ALLOC_CONTIGUOUS_MEM ioctl, which can be used to mmap a dma capable shared memory buffer into the user space process’s address space.
The mapped memory is allocated with dma_alloc_coherent() that returns physically contiguous memory from the dma region on arm64.
The beauty of this function is that it also maps the memory into the kernel virtual address space, however the returned vmalloc region address is not affected by KASLR, it only depends on the vmalloc allocation order.
As the contiguous dma memory is allocated in devdrv_continuous_mem_init() on device probe during kernel boot, the order of vmalloc allocations this early is deterministic, thus the kernel virtual address is stable and known.
The result is an extremely strong primitive, a memory buffer at a know kernel virtual address, that can be mapped into user space.
The contiguous shared memory can be used to create a fake sub info node while redirecting the stream_sub pointer of a selected stream info at it.
Once this stream is allocated, the fake sub info is linked into the per-process allocated stream list.
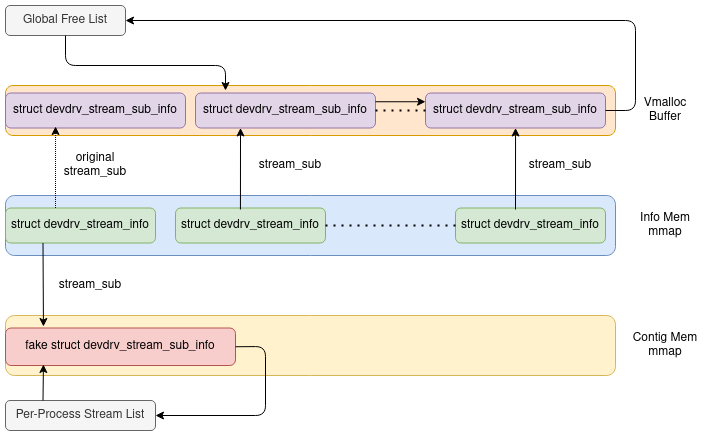
The figure denotes the state of the stream info structures after the alloc stream ioctl completes with the corrupted sub info
The per-process list head is contained within the proc_ctx structure which is kmallocated from the kernel heap.
After the linking in of the fake sub info the address of this structure is disclosed into the shared memory.
The leaked address is a kernel virtual address from the linear mapping region.
Before going any further with the exploitation let’s take a look at the different vendor KASLR implementations.
Kernel Memory 101
In order to have a meaningful discussion on the KASLR implementation we must look at the different regions within the virtual memory and how they are used.
This will be a very superficial introduction to the ARM64 memory management, for accurate details please consult the kernel sources and the relevant kernel and ARM64 documentation.
A handy tool to observe the page table block entries and the kernel virtual address space on a running kernel is the /sys/kernel/debug/kernel_page_tables file.
It can be enabled with the CONFIG_ARM64_PTDUMP_CORE and CONFIG_ARM64_PTDUMP_DEBUGFS kernel options.
An extract from the Huawei kernel is presented below.
---[ Modules start ]---
---[ Modules end ]---
---[ vmalloc() Area ]---
0xffffff8008000000-0xffffff8008010000 64K PTE RW NX SHD AF UXN DEVICE/nGnRE
0xffffff8008011000-0xffffff8008012000 4K PTE RW NX SHD AF UXN DEVICE/nGnRE
0xffffff8008013000-0xffffff8008014000 4K PTE RW NX SHD AF UXN DEVICE/nGnRE
0xffffff8008015000-0xffffff8008016000 4K PTE RW NX SHD AF UXN DEVICE/nGnRE
0xffffff8008017000-0xffffff8008018000 4K PTE RW NX SHD AF UXN DEVICE/nGnRE
0xffffff8008019000-0xffffff800801a000 4K PTE RW NX SHD AF UXN DEVICE/nGnRE
0xffffff800801b000-0xffffff800801c000 4K PTE RW NX SHD AF UXN DEVICE/nGnRE
0xffffff800801d000-0xffffff800801e000 4K PTE RW NX SHD AF UXN DEVICE/nGnRE
0xffffff800801f000-0xffffff8008020000 4K PTE RW NX SHD AF UXN DEVICE/nGnRE
...
0xffffff8049000000-0xffffff8049001000 4K PTE RW NX SHD AF UXN MEM/NORMAL
// Kernel Image
0xffffff8428c80000-0xffffff8428e00000 1536K PTE ro x SHD AF CON UXN MEM/NORMAL
0xffffff8428e00000-0xffffff842a200000 20M PMD ro x SHD AF BLK UXN MEM/NORMAL
0xffffff842a200000-0xffffff842a260000 384K PTE ro x SHD AF CON UXN MEM/NORMAL
0xffffff842a260000-0xffffff842a400000 1664K PTE ro NX SHD AF UXN MEM/NORMAL
0xffffff842a400000-0xffffff842aa00000 6M PMD ro NX SHD AF BLK UXN MEM/NORMAL
0xffffff842aa00000-0xffffff842aba0000 1664K PTE ro NX SHD AF UXN MEM/NORMAL
0xffffff842afa0000-0xffffff842b000000 384K PTE RW NX SHD AF CON UXN MEM/NORMAL
0xffffff842b000000-0xffffff842c400000 20M PMD RW NX SHD AF BLK UXN MEM/NORMAL
0xffffff842c400000-0xffffff842c420000 128K PTE RW NX SHD AF CON UXN MEM/NORMAL
0xffffff842c420000-0xffffff842c42c000 48K PTE RW NX SHD AF UXN MEM/NORMAL
0xffffffbebfdb0000-0xffffffbebfdba000 40K PTE RW NX SHD AF UXN MEM/NORMAL
0xffffffbebfdc8000-0xffffffbebfdd2000 40K PTE RW NX SHD AF UXN MEM/NORMAL
0xffffffbebfde0000-0xffffffbebfdea000 40K PTE RW NX SHD AF UXN MEM/NORMAL
0xffffffbebfdf8000-0xffffffbebfe02000 40K PTE RW NX SHD AF UXN MEM/NORMAL
0xffffffbebfe10000-0xffffffbebfe1a000 40K PTE RW NX SHD AF UXN MEM/NORMAL
0xffffffbebfe28000-0xffffffbebfe32000 40K PTE RW NX SHD AF UXN MEM/NORMAL
0xffffffbebfe40000-0xffffffbebfe4a000 40K PTE RW NX SHD AF UXN MEM/NORMAL
0xffffffbebfe58000-0xffffffbebfe62000 40K PTE RW NX SHD AF UXN MEM/NORMAL
0xffffffbebfe70000-0xffffffbebfff0000 1536K PTE RW NX SHD AF UXN MEM/NORMAL
---[ vmalloc() End ]---
---[ Fixmap start ]---
0xffffffbefe800000-0xffffffbefea00000 2M PMD ro NX SHD AF BLK UXN MEM/NORMAL
---[ Fixmap end ]---
---[ PCI I/O start ]---
---[ PCI I/O end ]---
---[ vmemmap start ]---
0xffffffbf2d000000-0xffffffbf35000000 128M PMD RW NX SHD AF BLK UXN MEM/NORMAL
0xffffffbf4d000000-0xffffffbf4e000000 16M PMD RW NX SHD AF BLK UXN MEM/NORMAL
---[ vmemmap end ]---
---[ Linear Mapping ]---
0xffffffcb40000000-0xffffffcb40080000 512K PTE RW NX SHD AF CON UXN MEM/NORMAL
// Kernel Image in linear memory
0xffffffcb40080000-0xffffffcb40200000 1536K PTE ro NX SHD AF UXN MEM/NORMAL
0xffffffcb40200000-0xffffffcb41e00000 28M PMD ro NX SHD AF BLK UXN MEM/NORMAL
0xffffffcb41e00000-0xffffffcb41fa0000 1664K PTE ro NX SHD AF UXN MEM/NORMAL
0xffffffcb41fa0000-0xffffffcb42000000 384K PTE RW NX SHD AF CON UXN MEM/NORMAL
0xffffffcb42000000-0xffffffcb50000000 224M PMD RW NX SHD AF CON BLK UXN MEM/NORMAL
0xffffffcb50000000-0xffffffcb50c00000 12M PMD RW NX SHD AF BLK UXN MEM/NORMAL
0xffffffcb50c00000-0xffffffcb50d00000 1M PTE RW NX SHD AF CON UXN MEM/NORMAL
0xffffffcb59300000-0xffffffcb59400000 1M PTE RW NX SHD AF CON UXN MEM/NORMAL
0xffffffcb59400000-0xffffffcb5a000000 12M PMD RW NX SHD AF BLK UXN MEM/NORMAL
0xffffffcb5a000000-0xffffffcb5e000000 64M PMD RW NX SHD AF CON BLK UXN MEM/NORMAL
0xffffffcb5f100000-0xffffffcb5f200000 1M PTE RW NX SHD AF CON UXN MEM/NORMAL
0xffffffcb5f200000-0xffffffcb60000000 14M PMD RW NX SHD AF BLK UXN MEM/NORMAL
0xffffffcb60000000-0xffffffcb6c000000 192M PMD RW NX SHD AF CON BLK UXN MEM/NORMAL
0xffffffcb6c000000-0xffffffcb6c200000 2M PMD RW NX SHD AF BLK UXN MEM/NORMAL
0xffffffcb6f000000-0xffffffcb6f100000 1M PTE RW NX SHD AF CON UXN MEM/NORMAL
0xffffffcb71060000-0xffffffcb71200000 1664K PTE RW NX SHD AF CON UXN MEM/NORMAL
0xffffffcb71200000-0xffffffcb72000000 14M PMD RW NX SHD AF BLK UXN MEM/NORMAL
0xffffffcb72000000-0xffffffcb80000000 224M PMD RW NX SHD AF CON BLK UXN MEM/NORMAL
0xffffffcb80000000-0xffffffcbc0000000 1G PGD RW NX SHD AF BLK UXN MEM/NORMAL
0xffffffcbc0000000-0xffffffcbe0000000 512M PMD RW NX SHD AF CON BLK UXN MEM/NORMAL
0xffffffcbf1280000-0xffffffcbf1400000 1536K PTE RW NX SHD AF CON UXN MEM/NORMAL
0xffffffcbf1400000-0xffffffcbf2000000 12M PMD RW NX SHD AF BLK UXN MEM/NORMAL
0xffffffcbf2000000-0xffffffcc20000000 736M PMD RW NX SHD AF CON BLK UXN MEM/NORMAL
0xffffffcc40000000-0xffffffcd40000000 4G PGD RW NX SHD AF BLK UXN MEM/NORMAL
0xffffffd340000000-0xffffffd360000000 512M PMD RW NX SHD AF CON BLK UXN MEM/NORMAL
The virtual address examples are specific to ARM64 with 39 virtual address bits and 4 kb page tables.
The first region (0xffffff8000000000 - 0xffffff8008000000) is reserved for kernel modules.
It is a 128 MB kernel virtual memory area used to decouple modules from the kernel image thus prevent them from leaking the kernel base address.
The second is the vmalloc region (0xffffff8008000000 - 0xffffffbebfff0000), this 256 GB address space is used to provide virtual address for various kernel resources.
Pointers acquired with vmalloc(), vmap(), vm_map_ram(), ioremap(), dma_alloc_coherent(), etc. are assigned a virtual address from this region.
Consecutive virtual addresses don’t necessarily relate to contiguous physical pages, they are not even necessarily backed by RAM.
Addresses are not randomized, they are reserved by the get_vm_area() call, that maintains an RB tree of unused areas within this region and uses a first fit algorithm to satisfy requests.
Still within the vmalloc region resides the virtual address of the kernel base image. Here, there is a significant difference between the Galaxy S20 and the P40 Pro. On Samsung, the kernel base image is loaded at a randomized address in the physical memory, with ~12 bits of entropy, however the virtual address is at a constant offset from the physical base. If either the physical or the virtual base is leaked the other can be calculated. On Huawei, the kernel is always loaded at a fixed physical address (0x80000), but the virtual base address is independently randomized with ~20 bits of entropy.
The 2 MB fixmap region (0xffffffbefe800000-0xffffffbefea00000) is used when a virtual address needs to be know at compile time, but the physical address can be changed later. As an example it is used by early ioremaps, when the kernel is already using the MMU, but the entire memory subsystem is not yet initialized. By definition the addresses in this region need to be known and cannot be randomized.
The vmemmap region (0xffffffbf00000000 - 0xffffffc000000000) is used to access the struct page array, where each physical memory page has an associated struct page entry.
The size of this region is 4GB, however the actual size of the page array is significantly smaller (~128 MB).
On the Galaxy S20 both the vmemmap and the linear mapping begins at a fixed address and they are not randomized.
On the Huawei phones they are both randomized with the same seed, the addresses containing around 8 bits of entropy, consequently the base address of the vmemmap can be calculated from the linear map base and vice versa.
The linear map is used to address the entire physical memory, pages consecutive in the physical memory are also consecutive in this virtual memory range. It is sometimes also referred to as direct mapping or in security publications as physmap. The base address of this region must be gigabyte aligned which makes the address randomization rather coarse. There are also “holes” in this address space as the physical RAM’s bus addresses are not necessarily consecutive and there might be reserved RAM areas, outside of the scope of the kernel. Since the physical address of the kernel is not randomized on Huawei it can be located within the linear memory if the base address of the linear mapping is known.
The kernel divides the physical memory into zones, that can be used to satisfy different types of memory request.
The largest zone is used to provide dynamic memory for the kernel whenever it needs to allocate memory for any reason.
When the kernel requests consecutive pages with __get_free_pages() or alloc_pages() their linear address is returned.
Besides the kernel’s dynamic data the user space processes’ memory pages can also be accessed through the linear map, when they are swapped in.
Breaking KASLR
The proc_ctx structure is allocated with kmalloc which uses __get_free_pages() when creating new slabs thus the leaked address is a linear address.
Unless we knew somehow the associated physical address it is not possible to directly calculate the linear map base from this leak.
Kernel heap allocations are not deterministic enough to reasonably guess the physical location, in theory the leaked address could be anywhere within the region.
The saving grace is the coarse 1 GB alignment of the linear mapping base address.
Because of that, we don’t need to know the exact location of the object in the physical memory, instead it is enough to know at which GB offset it resides.
Then the base address could be calculated by applying a mask and subtracting the GB offset from the leaked address.
Since the device only has 8 GB of physical memory even the most naive approach would yield a 12.5% success chance.
Fortunately, this can be significantly improved by profiling heap allocations and massaging the zone allocator.
The kernel uses the buddy allocator to reserve memory from a zone when alloc_pages() is called.
The buddy allocator can only satisfy requests for power of two number of pages.
It does so by maintaining a list of free blocks, searching it for the first large enough block and then splitting the block into halves until it matches the requested size.
The proc_ctx structure is allocated when the /dev/davinci0 character device is opened.
Before doing that, the PoC sprays page size kernel allocations to exhaust scattered free blocks in the zone allocator’s list.
Then it sprays the target slab to force the proc_ctx allocation into a freshly allocated slab.
This way it is possible to have the object at a fairly deterministic physical location, where the GB offset can be guessed.
I determined the optimal number of spray object by empirical experiments (yes, I monkeyd around with it until it worked most of the time). I was able to reach the quality I expect from my PoCs, which means that they crash rarely enough not to be annoying. I suspect this method could be further engineered to be reliable enough for an actual exploit. However, the devices memory layout, thus the exact spray details, would always remain SoC specific.
Of course, the double free vulnerability could be used to leak the actual kernel base virtual address with a very high probability.
As explained in Longterm Security’s Exploiting a Single Instruction Race Condition in Binder blog post’s KASLR Leak section, signalfd and struct seq_operation objects could be leveraged to do that.
Unsafe Unlink
At this point we have an allocated stream info where the stream_sub pointer points to a fake sub info structure in the shared memory, and it is linked into the per-process stream list.
The address of the proc_ctx structure is leaked, from which the linear mapping base can be calculated thus the linear address of the kernel image is known.
It is time to look at the stream release implementation.
When the stream free ioctl is called, eventually the devdrv_proc_free_stream() function is executed.
It takes the supplied stream id and finds the associated stream info structure in the “info” shared memory ([8]).
Once it gets a hold of the stream it dereferences the stream_sub pointer ([9]), then it calls list_del on it ([10]).
The list_del helper function does a simple double linked list unlink on the sub info node.
Finally, devdrv_free_stream() adds back the node into the global free list.
int devdrv_proc_free_stream(struct devdrv_proc_ctx* proc_ctx, u32 stream_id)
{
struct devdrv_stream_info* stream_info = NULL;
struct devdrv_stream_sub_info *stream_sub_info = NULL;
[...]
dev_id = proc_ctx->devid;
// [8]
stream_info = devdrv_calc_stream_info(dev_id, stream_id);
if (stream_info == NULL) {
NPU_DRV_ERR("stream_info is NULL. stream_id=%d\n", stream_id);
return -1;
}
// [9]
stream_sub_info = (struct devdrv_stream_sub_info*)stream_info->stream_sub;
if (test_bit(stream_id, proc_ctx->stream_bitmap) == 0) {
NPU_DRV_ERR(" has already been freed! stream_id=%d \n", stream_id);
return -1;
}
// [10]
list_del(&stream_sub_info->list);
ret = devdrv_free_stream(proc_ctx->devid, stream_id, &sq_send_count);
if (ret != 0) {
NPU_DRV_ERR("npu process %d free stream_id %d failed \n", current->pid, stream_id);
return -1;
}
proc_ctx->send_count += sq_send_count;
bitmap_clear(proc_ctx->stream_bitmap, stream_id, 1);
if (stream_id < DEVDRV_MAX_NON_SINK_STREAM_ID) {
proc_ctx->stream_num--;
} else {
proc_ctx->sink_stream_num--;
}
NPU_DRV_DEBUG("npu process %d left stream num = %d sq_send_count = %d "
"(if stream'sq has been released) now\n",
current->pid, proc_ctx->stream_num, sq_send_count);
return 0;
}
Samsung kernels are compiled with CONFIG_DEBUG_LIST kernel option set.
This causes the __list_del_entry_valid() function to be executed when list_del is called on a list_head node.
The check verifies that prev->next and next->prev pointers both point at the node that is to be deleted.
On Huawei there is no such protection, the vanilla list_del function is called, which is susceptible to the unsafe unlink attack if the unlinked node is controlled.
static inline void __list_del(struct list_head * prev, struct list_head * next)
{
next->prev = prev;
WRITE_ONCE(prev->next, next);
}
static inline void list_del(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
entry->next = LIST_POISON1;
entry->prev = LIST_POISON2;
}
Remember that the hijacked sub info node is located in the mmapped memory that the user space can write. With both the prev and next pointer controlled it is possible to write a controlled value at an arbitrary kernel virtual address. The only caveat is that the value also needs to be a valid kernel pointer that can be written. This restricted value write can easily be turned into a truly arbitrary value write the following way. The prev pointer is set to point at the destination that needs to be written. The next pointer (the value to be written) can point into the contiguous shared memory at the known kernel virtual address, after where the sub info node is. This shared memory is more than a page in size, and contains no meaningful data, thus the least significant byte of the value pointer can be set to any selected value. The pointer would still remain within the bounds of the shared memory. The result is a completely controlled byte written at the target location and the next seven bytes trashed by the rest of the pointer value. Fortunately, arm64 supports unaligned access (conditions apply, certain memory types such as device do not support it), therefore the target address can be incremented and the whole process can be repeated.
The final primitive can write arbitrary number of consecutive bytes with a chosen value at a chosen kernel virtual address. The only drawback is that the next seven bytes after the final byte written will be overwritten by uncontrolled values.
Sharing is Caring
With an arbitrary write and known kernel data address there are many ways to finish the exploit. My goal was to reach a convenient, truly arbitrary read-write primitive and explore Huawei’s anti-root solutions later. As we have seen already the NPU kernel driver allocates most of the memory, that can be mapped to user space, upon device probe. As it turns out, the addresses of these different memory regions are stored in a global array.
struct devdrv_mem_info {
phys_addr_t phy_addr;
vir_addr_t virt_addr;
size_t size;
};
struct devdrv_mem_info g_shm_desc[NPU_DEV_NUM][DEVDRV_MAX_MEM];
static struct devdrv_continuous_mem g_continuous_mem[NPU_DEV_NUM];
When the devdrv_info_sq_cq_mmap() mmap handler is called, it retrieves the physical address and the size of the different regions (sq, info, doorbell) from this array.
It calls remap_pfn_range() to map the selected physical memory into the process’ VMA.
int devdrv_info_sq_cq_mmap(u8 dev_id, const struct file *filep, struct vm_area_struct *vma) {
[...]
phy_addr = g_shm_desc[dev_id][DEVDRV_DOORBELL_MEM].phy_addr;
size = g_shm_desc[dev_id][DEVDRV_DOORBELL_MEM].size;
COND_RETURN_ERROR(size <= 0, -ENOMEM, "npu dev %d illegal doorbell cfg size = %lu\n", dev_id, size);
NPU_DRV_DEBUG("npu dev %d doorbell mem:user_virt_addr = 0x%lx, "
"phys_addr = 0x%llx, size = %lu\n", dev_id, start_addr, phy_addr, size);
err = remap_pfn_range(vma, start_addr, phy_addr >> PAGE_SHIFT, size, vma->vm_page_prot);
COND_RETURN_ERROR(err != 0, -EINVAL, "npu dev_id %d doobell register mmap failed\n", dev_id);
[...]
}
The layout of the struct devdrv_mem_info is quite lucky for the list unlink primitive as the virt_addr field that succeeds the phy_addr field is never used for most region types.
This way the phy_addr can be rewritten and it doesn’t matter that the primitive trashes the next field.
Even the size field can be overwritten for the doorbell entry as the next entry in the array is never used.
By overwriting the doorbell regions entry in the g_shm_desc array it is possible to mmap any physical memory into the user space for reading and writing.
While there is no explicit size check, a consecutive mapping is created 32 MB after the doorbell region, so at most 32 MB can be mapped.
Initially, I attempted to map the entire kernel text and overwrite it through the mapping. The mmap was successful and it was possible to read the kernel text, but write attempts caused unknown bus faults and consequently kernel panics. I strongly suspect that the kernel text is protected by the hypervisor, similarly to Galaxy kernels. I tried the same with the kernel page tables with similar results. Unboxing and comparing the hypervisors is a topic for a whole other blog post. For the interested reader Alexandre Adamski’s blog post provides great insight into the capabilities, the implementation details and the exploitation of Samsung’s hypervisor.
The PoC mmaps the entire kernel data section.
This way, besides having read-write access to the entire kernel data section, it is really easy to reuse this mmap primitive as the g_shm_desc is within this map itself.
Thus any 32 MB physical memory can be mapped to user space with relative ease.
Can We Get More Arbitrary?
Technically, at this point we already have an arbitrary kernel-read write primitive, however there are ways to improve it. The kernel data/bss section isn’t considered shared memory by any means. When the kernel data is written through the user space mapping the cached kernel addresses are not flushed, thus the kernel does not see the changes immediately. Any time the PoC wants to map a different 32 MB chunk and overwrites the doorbell descriptor it needs to wait until the previous value is evicted from the cache.
The final stage of the exploit walks the struct task_struct structures until it finds its own task_struct.
It reads the mm field that points to its struct mm_struct descriptor, that contains the address of its top level page table.
As it turns out process page tables are not protected against any kind of modification.
The PoC modifies its own page table this way to map the entire physical memory into its address space.
The result is a truly complete and convenient arbitrary read-write primitive.
Demo
Here is a high definition video capture of the PoC doing its thing on a P40 Pro.
Summary
The emergence of hardware assisted neural computing led to the addition of new subsystems on both Huawei and Samsung devices. As is the case with many new and complex software components both implementation contained exploitable security vulnerabilities. While the identified vulnerabilities were more impactful in the Huawei driver, which led to an arguably less challenging exploit, the access control defaults were stricter on Huawei originally. I was also pleasantly surprised by the kernel mitigation features of the platform. The P40 kernel comes with freelist hardening and randomization enabled, the linear memory is randomized and the secure memcpy implementation is effective at preventing exploitable integer overflows. On the other hand Huawei lacks a linked list hardening feature, like the Galaxy S20’s debug list, that would prevent unlink attacks from a list node corruption.