Additional posts in this series:
In my Basebanheimer talk at Hardwear.io, I explained a method for exploiting the Mediatek Baseband Pivot vulnerability CVE-2022-21765 for arbitrary code execution in the Linux kernel on Mediatek’s older (“Helio”) chipsets, which use 32-bit kernels.
I also mentioned that using previous ideas, the vulnerability could theoretically be exploited on Mediatek’s newest chipset family (Dimensity, which uses 64-bit kernels) as well.
After the conference, with my college Lorant Szabo we have completed this exercise.
The vulnerabilities: CVE-2022-21765 and CVE-2022-21769
To recap, the vulnerabilities provide an OOB read/write in the Linux kernel driver that implements the Application (AP) and Cellular Processor (CP) interface, which Mediatek calls the CCCI driver. In particular, the bugs are due to the ringbuffer implementation not verifying the sanity of the offset and length values used for the ringbuffers that are stored in shared memory between the AP and the CP. Here’s the code in question (see the talk video for more explanation):
 }
}
It’s not entirely smooth sailing from here, though, as the OOB primitives we get are limited.
First of all, we can only go maximum 2*UINT_MAX out-of-bounds. Secondly, and crucially, since we are corrupting the offsets that the kernel is using for its ringbuffer actions, we don’t directly control:
- where the read action is read into (i.e. the destination where an OOB read “leaks”),
- where the write action is writing from (i.e. the written values)
Exploiting ioremap OOB Bugs in the Linux Kernel
In a total coincidence, after finishing our exploit for Dimensity, we’ve seen the latest Tesla pwn talk from p0ly and Vincent Dehors. They have presented an incredible exploit chain, which in its final step happens to exploit a remarkably similar vulnerability in a similar way. It’s amazing how completely different vendors manage to replicate the same issues.
Their approach shared traits with the original ideas from Brandon Azad: targeting other allocations in the vmalloc region (these ringbuffers are ioremap()ed, which is serviced from the vmalloc region).
As described in the Basebanheimer talk, we similarly went with this idea from Brandon and tried targeting a kernel thread stack allocated with _do_fork.
So this gives an idea of a target to overwrite, but we still need to figure out a few things:
- can we turn the limited OOB R/W primitives into ones where the values written are controlled enough
- how can we bypass KASLR
- can we get a predictable vmalloc region shape on our target that allows us to select a suitable
_do_forkvictim
Improving the OOB Primitives of CVE-2022-21765/CVE-2022-21769
The AP and CP use several ringbuffers, but most of them are very noisy, which is a problem for exploitation.
Luckily, we found that the ringbuffer used only for the Remote Filesystem (RemoteFS) implementation becomes very silent post initial boot. So this gave us a ringbuffer to exploit without having to worry about racing the normal behavior.
Even better, the RemoteFS APIs gave us the perfect primitives to turn the OOB Primitives into (almost) fully controlled reads and writes:
- in order to write memory, we can first use the regular File Write API of RemoteFS to prepare controlled data,
- then, we can read it “back” with the File Read API and use the
CVE-2022-21765OOB write primitive to create the write-what-where, - we can do the same thing in reverse in order to get arbitrary memory read (read-from-where) as well: corrupt ringbuffers on File Write to store the desired leaked memory into a file and then use the File Read API as intended to read it back.
One limitation we have to keep in mind for the write-what-where is that the values written aren’t entirely controlled, because each ringbuffer write contains a header and footer, as you can see in the image below:
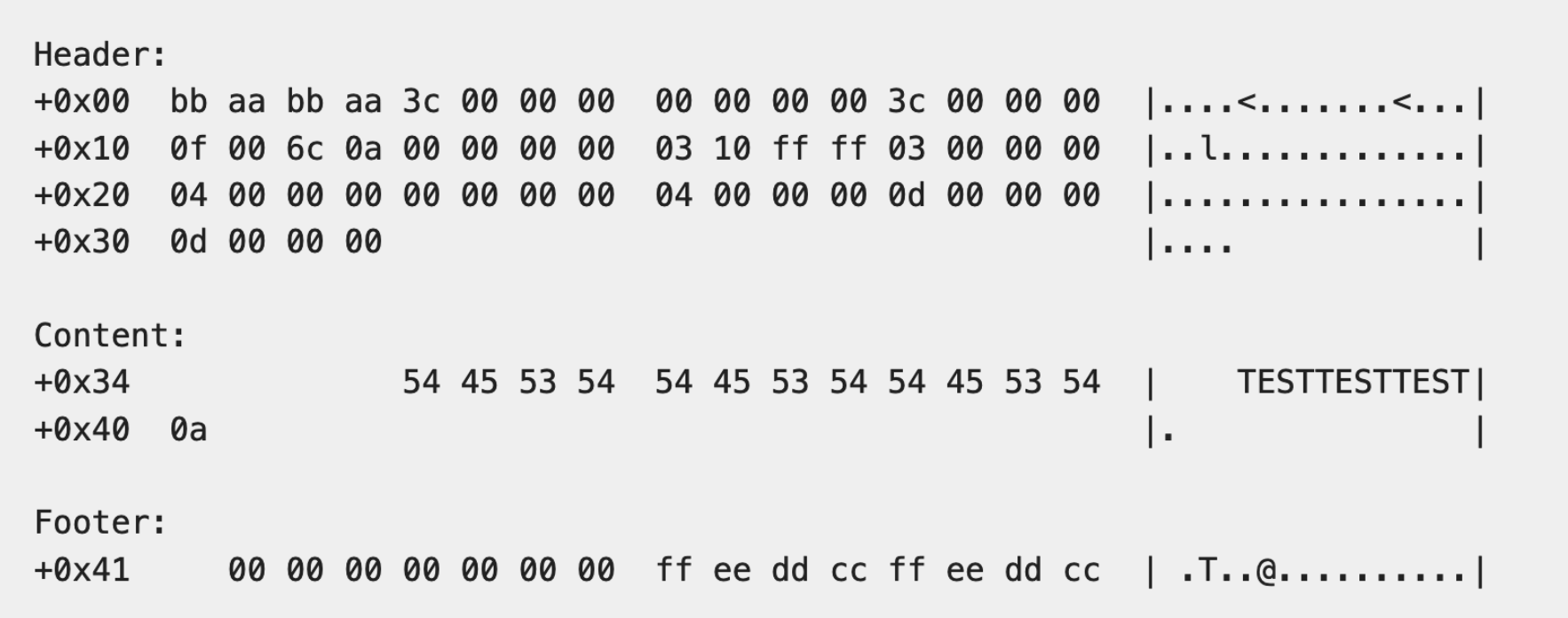
So we have to be able to pick a corruption target that can tolerate the side-effect of adjacent bytes being overwritten with the header/footer “junk”.
Finding a Reliable Vmalloc Victim and Bypassing KASLR
Looking at /proc/vmallocinfo, we find a ton of viable targets, including thread stacks and bpf programs.
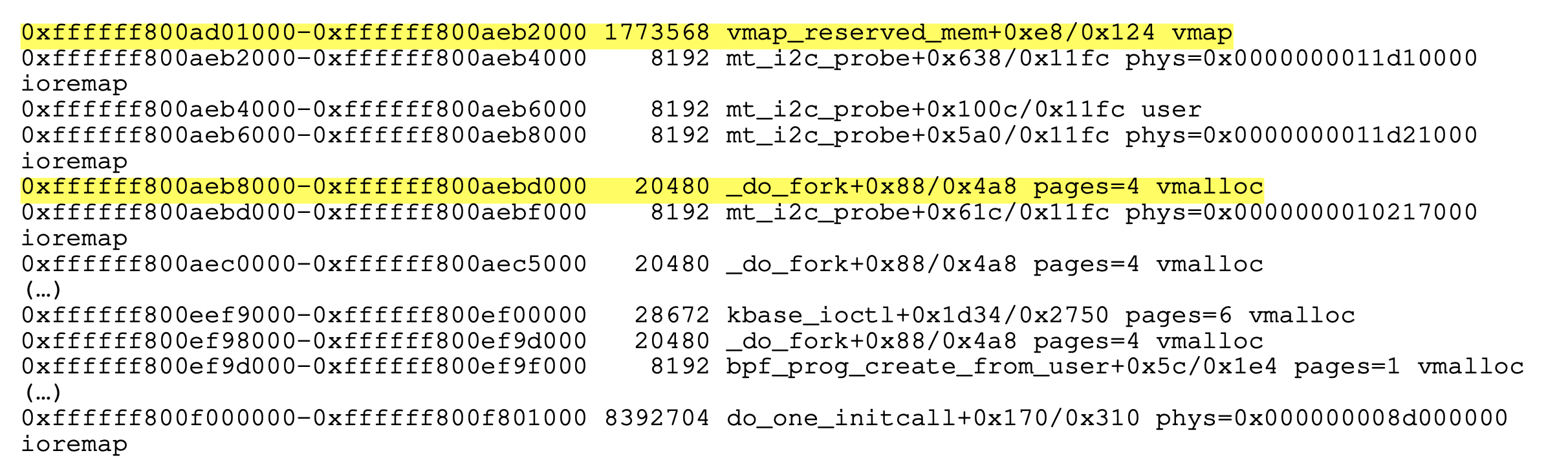
Although vmalloced addresses do not have KASLR randomization applied to them, layouts aren’t completely static as the “natural” entropy provided by the runtime is there.
Still, early allocations will have predictable, reliable patterns. As others in similar situations have found previously (e.g. 1 and 2), since our allocation comes from a very early vmalloc, it ends up at a predictable address, and neighboring allocations are also predictable with good accuracy.
From here, we were able to identify _do_fork allocations in vmalloc that we could reliably target.
 }
}
To recap, a _do_fork allocation in the vmalloc region represents a thread stack in the kernel. These are used by the user space threads during syscall execution, but also used by kernel threads to store their execution stacks.
Kernel threads in particular have a fairly predictable call stack, because the Linux scheduler spawns them the exact same way. So the top of these stack are the pushed stack frames of ret_from_fork, worker_thread, kthread, schedule, etc.
Consequently, by overwriting the corresponding stack frame of a kernel thread that is scheduled in such that we can reliably and easily “race” its scheduling with our overwrites, we can hijack the execution of that kernel thread, create a ROP-chain, and from there execute custom code.
 }
}
In addition, using such a target we also get an instant win for KASLR bypass. In our case, we found that at +0x3eb8 from our RemoteFS ringbuffer we consistently get a region (same as the one that’s viable as our overwrite target) containing a fixed pointer to kthread, which made leaking the kernel image KASLR slide straightforward.
ROP Chain for Kernel RCE
p0ly and Vincent Dehors used the classic approach for their ROP of overwriting the poweroff_cmd string and then calling poweroff_work_func from the ROP. This is nice and clean but the drawback is that you “only” get to execute commands as a kworker root user.
Back in the day, that would have been game over, but nowadays SELinux on modern Androids restricts that user so heavily that it can do almost nothing. It can’t even run a connect-back shell because it doesn’t have privileges to open network sockets. So for a smartphone with a Mediatek Dimensity chipset, we needed something more powerful.
Brandon Azad used the ___bpf_prog_run() ROP technique. However, this was not workable for us, because Mediatek kernels prevent this method.
In particular, Mediatek Dimensity kernels turn out to be shipped with BPF JIT compiling forced, which results in omitting this API from the kernel altogether:
#ifndef CONFIG_BPF_JIT_ALWAYS_ON
static unsigned int ___bpf_prog_run(u64 *regs, const struct bpf_insn *insn,
u64 *stack)
...
What we did instead was look at the BPF JIT implementation we had. As it turns out, the necessity to always JIT the eBPF programs means that the module_alloc call (that simply allocates RWX memory for the caller) is there in the kernel. This provides a perfect trampoline for a ROP chain to arbitrary shellcode, of course.
void *module_alloc(unsigned long size)
{
u64 module_alloc_end = module_alloc_base + MODULES_VSIZE;
gfp_t gfp_mask = GFP_KERNEL;
void *p;
...
p = __vmalloc_node_range(size, MODULE_ALIGN, module_alloc_base,
module_alloc_end, gfp_mask, PAGE_KERNEL_EXEC, 0,
NUMA_NO_NODE, __builtin_return_address(0));
...
We still had to find gadgets to prepare the necessary register values for the steps of the ROP chain. Unlike the case of 1, we needed to have better control than one register in a one-shot, which needs just a little bit more finesse.
One difficulty was posed by the fact that functions like memcpy in the Linux kernel are normally optimized so much that they don’t even use the stack (ergo their epilogue doesn’t provide for convenient ROP gadget chaining), as they must work in such early boot stage when stack isn’t even initialized yet. Nonetheless, luckily there are wrappers around memcpy which add stack usage. (You can compare this to the approach in 3 where they made use of copy_from_user in a similar manner.)
Finally, we can use our ROP memcpy to copy the desired shellcode from a reliable fixed address to the new RWX region. In our case, we were able to go back once again to our do_fork thread stack and use the top of that stack frame as our staging area.
When stitched together, the steps of the ROP chain until we get to execute fully arbitrary shellcode:
1. set x0 = 0x100 (size of the injected code), x1 = <dummy>
2. module_alloc(x0:size) -> x0:dst
3. set x8 = x0
4. set x0 = 0x100 (size of the injected code), x1 = <dummy>
5. set x2 = x0
6. set x0 = <dummy>, x1 = <code source>
7. set x0 = x8
8. memcpy(x0:dst, x1:src, x2:size) (preserves x0)
9. set x8 = x0
10. jump on x8
Exploit Demo
Finally, here’s a video demonstration of exploiting the vulnerability for RCE on a Dimensity chipset device (a Xiaomi POCO M3 5G):
As the video shows, for the sake of simplicity the poc just executes shellcode that sets all registers to a unique pattern, to showcase that the execution worked (excerpt from the poc source):
#define __SHELLCODE_SIZE__ (0x100)
const int shellcode_size = __SHELLCODE_SIZE__;
const ulong shellcode_addr = target_vmalloc + 0x1000;
uint shellcode[__SHELLCODE_SIZE__/4] = {
0x00000000, // padding for exploit_write
0xd2802020, // mov x0, #0x101
0xd2802221, // mov x1, #0x111
0xd2802422, // mov x2, #0x121
0xd2802623, // mov x3, #0x131
0xd2802824, // mov x4, #0x141
0xd2802a25, // mov x5, #0x151
0xd2802c26, // mov x6, #0x161
0xd2802e27, // mov x7, #0x171
0xd2803028, // mov x8, #0x181
(...)
0xd280563a, // mov x26, #0x2b1
0xd280583b, // mov x27, #0x2c1
0xd2805a3c, // mov x28, #0x2d1
0xd2805c3d, // mov x29, #0x2e1
0xd2805e3e, // mov x30, #0x2f1
0xd65f03c0, // ret
};